1.2. Phá mã vi sai trên TinyDES¶
1.2.1. Mô tả TinyDES¶
TinyDES là một phiên bản thu nhỏ của chuẩn mã hóa DES. TinyDES là mã hóa khối theo mô hình Feistel, kích thước khối là \(8\) bit, kích thước khóa cũng là \(8\) bit. Mỗi vòng khóa con có độ dài \(6\) bit.
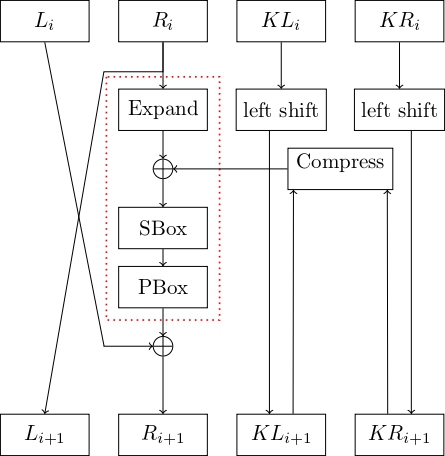
Hình 1.35 Một vòng TinyDES¶
Mã TinyDES khá đơn giản. Theo mô hình Feistel, khối đầu vào \(8\) bit được chia thành hai nửa trái phải \(4\) bit. Nửa phải sẽ đi qua các hàm Expand, SBox và PBox, sau đó XOR với nửa trái để được nửa phải mới. Còn nửa trái mới là nửa phải cũ. Tóm lại công thức mô hình Feistel là:
với \(i = 1, 2, 3\) tương ứng \(3\) vòng với đầu vào của khối là \((L_0, R_0)\).
Chúng ta cần các động tác sau:
Expand: mở rộng và hoán vị \(R_i\) từ \(4\) bits lên \(6\) bits. Giả sử \(4\) bits của \(R_i\) là \(b_0 b_1 b_2 b_3\) thì kết quả sau khi Expand là \(b_2 b_3 b_1 b_2 b_1 b_0\).
SBox: gọi \(6\) bits đầu vào là \(b_0 b_1 b_2 b_3 b_4 b_5\). Khi đó ta tra cứu theo bảng SBox với \(b_0 b_5\) chỉ số hàng, \(b_1 b_2 b_3 b_4\) chỉ số cột. Nói cách khác bảng SBox có \(4\) hàng, \(16\) cột. Kết quả của SBox là một số \(4\) bit.
PBox: là hàm hoán vị \(4\) bits \(b_0 b_1 b_2 b_3\) thành \(b_2 b_0 b_3 b_1\).
Như vậy, hàm \(F\) của mô hình Feistel đối với mã TinyDES là:
Để sinh khóa con cho \(3\) vòng, khóa ban đầu được chia thành hai nửa trái phải lần lượt là \(KL_0\) và \(KR_0\). TinyDES thực hiện như sau:
Vòng 1: \(KL_0\) và \(KR_0\) được dịch vòng trái \(1\) bit để được \(KL_1\) và \(KR_1\);
Vòng 2: \(KL_1\) và \(KR_1\) được dịch vòng trái \(2\) bit để được \(KL_2\) và \(KR_2\);
Vòng 3: \(KL_2\) và \(KR_2\) được dịch vòng trái \(1\) bit để được \(KL_3\) và \(KR_3\).
Khi đó, khóa \(K_i\) ở vòng thứ \(i\) (với \(i = 1, 2, 3\)) là hoán vị và nén \(8\) bits của \(KL_i\) và \(KR_i\) lại thành \(6\) bits.
Đặt \(8\) bits khi ghép \(KL_i \Vert KR_i\) là \(k_0 k_1 k_2 k_3 k_4 k_5 k_6 k_7\), kết quả là \(6\) bits \(k_5 k_1 k_3 k_2 k_7 k_0\).
tinydes.py
# tindeys.py
sbox = [
0xE, 0x4, 0xD, 0x1, 0x2, 0xF, 0xB, 0x8, 0x3, 0xA, 0x6, 0xC, 0x5, 0x9, 0x0, 0x7,
0x0, 0xF, 0x7, 0x4, 0xE, 0x2, 0xD, 0x1, 0xA, 0x6, 0xC, 0xB, 0x9, 0x5, 0x3, 0x8,
0x4, 0x1, 0xE, 0x8, 0xD, 0x6, 0x2, 0xB, 0xF, 0xC, 0x9, 0x7, 0x3, 0xA, 0x5, 0x0,
0xF, 0xC, 0x8, 0x2, 0x4, 0x9, 0x1, 0x7, 0x5, 0xB, 0x3, 0xE, 0xA, 0x0, 0x6, 0xD
]
def Xor(a: list[int], b: list[int]) -> list[int]:
return [x^y for x, y in zip(a, b)]
def Expand(R: list[int]) -> list[int]:
return [R[2], R[3], R[1], R[2], R[1], R[0]]
def SBox(R: list[int]) -> list[int]:
row = int("".join(map(str, [R[0], R[5]])), 2)
col = int("".join(map(str, R[1:5])), 2)
return list(map(int, format(sbox[row*16 + col], "04b")))
def PBox(R: list[int]) -> list[int]:
return [R[2], R[0], R[3], R[1]]
def PBox_inv(R: list[int]) -> list[int]:
return [R[1], R[3], R[0], R[2]]
def Compress(K: list[int], round: int) -> list[int]:
left, right = K[:4], K[4:]
if round == 0 or round == 2:
left = left[1:] + left[:1]
right = right[1:] + right[:1]
elif round == 1:
left = left[2:] + left[:2]
right = right[2:] + right[:2]
Ki = left + right
return left, right, [Ki[5], Ki[1], Ki[3], Ki[2], Ki[7], Ki[0]]
def encrypt_block(plaintext: list[int], key: list[int]) -> list[int]:
keys = [key]
left, right = key[:4], key[4:]
for i in range(3):
left, right, key = Compress(left + right, i)
keys.append(key)
left, right = plaintext[:4], plaintext[4:]
for i in range(3):
left, right = right, Xor(left, PBox(SBox(Xor(Expand(right), keys[i+1]))))
return left + right
#print(encrypt_block([0, 1, 0, 1, 1, 1, 0, 0], [1, 0, 0, 1, 1, 0, 1, 0]))
1.2.2. Phá mã vi sai trên TinyDES¶
Giả sử \(X_1\) và \(X_2\) là hai khối input có cùng số bit.
Ta định nghĩa vi sai của \(X_1\) và \(X_2\) là \(X = X_1 \oplus X_2\).
Xét các phép biến đổi trong TinyDES
1.2.2.1. Phép XOR key¶
Gọi \(K\) là khóa con ở vòng nào đó trong thuật toán. Khi đó nếu đặt \(Y_1 = X_1 \oplus K\) và \(Y_2 = X_2 \oplus K\) thì vi sai của output là \(Y = Y_1 \oplus Y_2 = X_1 \oplus X_2\). Như vậy \(K\) không tác động lên vi sai và đây là tính chất quan trọng để chúng ta phá mã vi sai.
1.2.2.2. Phép PBox¶
Phép PBox bảo toàn số bit (hoán vị \(4\) bits thành \(4\) bits) và cách xây dựng hoán vị là một biến đổi tuyến tính. Việc hoán vị \(4\) bits \(b_0 b_1 b_2 b_3\) thành \(b_2 b_0 b_3 b_1\) tương đương với phép nhân ma trận
Do đó nếu đặt \(Y_1 = \mathsf{PBox}(X_1)\) và \(Y_2 = \mathsf{PBox} (X_2)\) thì
Như vậy nếu vi sai input là cố định thì vi sai output cũng cố định do tính tuyến tính.
1.2.2.3. Phép Expand¶
Tương tự, phép Expand cũng là biến đổi tuyến tính và nếu đặt \(Y_1 = \mathsf{Expand}(X_1)\) và \(Y_2 = \mathsf{Expand}(X_2)\) thì
Cũng tương tự, nếu vi sai input là cố định thì vi sai output cũng cố định.
1.2.2.4. Phép SBox¶
Phép SBox là một biến đổi không tuyến tính với input \(6\) bits và output \(4\) bits.
Đặt \(Y_1 = \mathsf{SBox}(X_1)\) và \(Y_2 = \mathsf{SBox}(X_2)\).
Với mỗi \(X = X_1 \oplus X_2\) cố định thì cứ một giá trị \(X_1\) sẽ có duy nhất một giá trị \(X_2\) cho ra vi sai \(X\). Tuy nhiên vi sai output \(Y_1 \oplus Y_2\) phân bố không đều nhau.
Thực hiện bruteforce đơn giản trên SBox với vi sai input \(X = X_1 \oplus X_2\) có \(6\) bits, ta tìm được sự phân bố vi sai output \(Y = Y_1 \oplus Y_2\).
Chúng ta mong muốn rằng trên một hàng có càng ít phần tử khác \(0\) càng tốt. Từ đó sự phân bố xác suất sẽ dễ kiểm soát hơn.
check_sbox.py
# check_sbox.py
import tinydes
def int_to_vec6(n: int) -> list[int]:
return list(map(int, format(n, "06b")))
def int_to_vec8(n: int) -> list[int]:
return list(map(int, format(n, "08b")))
def vec_to_int(v: list[int]) -> int:
return int("".join(map(str, v)), 2)
# Know about distribution of differential input-output
dist = []
for _ in range(2**6):
X = int_to_vec6(_)
row = [0] * 16
for __ in range(2**6):
X1 = int_to_vec6(__)
X2 = tinydes.Xor(X, X1)
Y1 = tinydes.SBox(X1)
Y2 = tinydes.SBox(X2)
Y = tinydes.Xor(Y1, Y2)
row[vec_to_int(Y)] += 1
dist.append(row)
for i, row in enumerate(dist):
print(f'Row = {row}')
print(f'Row {i} has {row.count(0)} zero elements')
print(f'Element that has maximal probability is {row.index(max(row))} with prob {max(row)}')
print()
Sau khi xem bảng phân phối vi sai input và output ta có thể thấy được rằng:
Nếu vi sai input \(X = 0\) thì chắc chắn vi sai output \(Y = 0\).
Nếu vi sai input \(X = 16\) thì có \(9\) vi sai output \(Y\) khác \(0\).
Nếu vi sai input \(X = 52\) thì có \(8\) vi sai output \(Y\) khác \(0\).
Dựa trên nhận xét này, chúng ta sẽ tấn công trên các \(X_1\), \(X_2\) mà \(X = X_1 \oplus X_2 \in \{ 16, 52 \}\).
Xét hai hàng \(16\) và \(52\), ta thấy rằng:
Nếu vi sai input \(X = 16\) thì vi sai output \(Y = 7\) là cao nhất với xác suất \(14/64\).
Nếu vi sai input \(X = 52\) thì vi sai output \(Y = 2\) là cao nhất với xác suất \(16/64\).
1.2.2.5. Hàm \(F\)¶
Như vậy, phép XOR key, phép PBox và phép Expand cho xác suất đều nhau với các cặp vi sai \((X, Y)\). Trong khi đó thì SBox lại cho xác suất các cặp vi sai \((X, Y)\) không đều nhau.
Đặt \(Y_1 = F(X_1)\) và \(Y_2 = F(X_2)\).
Đi từ trong ra ngoài (\(\mathsf{Expand}\), tới \(\mathsf{SBox}\), tới \(\mathsf{PBox}\) và cuối cùng là \(F\)) ta thấy rằng:
vi sai input của hàm \(F\) chính là vi sai input của \(\mathsf{Expand}\);
vi sai output của \(\mathsf{Expand}\) là vi sai input của \(\mathsf{SBox}\) (không phụ thuộc vào khóa);
vi sai output của \(\mathsf{SBox}\) là vi sai input của \(\mathsf{PBox}\);
vi sai output của \(\mathsf{PBox}\) là vi sai output của hàm \(F\).
Ta có thể đưa ra nhận xét về xác suất vi sai output \(Y = Y_1 \oplus Y_2\) từ vi sai \(X = X_1 \oplus X_2\) như sau:
Nếu vi sai input của \(F\) là \(0\) \(\Rightarrow\) vi sai output của \(\mathsf{Expand}\) là \(0\) \(\Rightarrow\) vi sai output của \(\mathsf{SBox}\) chắc chắn là \(0\) \(\Rightarrow\) vi sai output của \(\mathsf{PBox}\) chắc chắn là \(0\) \(\Rightarrow\) vi sai output của hàm \(F\) chắc chắn là \(0\).
Nếu vi sai input của \(F\) là \(1\) \(\Rightarrow\) vi sai output của \(\mathsf{Expand}\) là \(16\) \(\Rightarrow\) vi sai output của \(\mathsf{SBox}\) là \(7\) với xác suất \(14/64\) \(\Rightarrow\) vi sai output của \(\mathsf{PBox}\) là \(11\) với xác suất là \(14/64\) \(\Rightarrow\) hàm \(F\) là \(11\) với xác suất \(14/64 = 7/32\).
Nếu vi sai input của \(F\) là \(3\) \(\Rightarrow\) vi sai output của \(\mathsf{Expand}\) là \(52\) \(\Rightarrow\) vi sai output của \(\mathsf{SBox}\) là \(2\) với xác suất \(16/64\) \(\Rightarrow\) vi sai output của \(\mathsf{PBox}\) là \(8\) với xác suất \(16/64\) \(\Rightarrow\) hàm \(F\) là \(8\) với xác suất \(16/64 = 1/4\).
Nói chung, chúng ta chọn output của \(\mathsf{Expand}\) (input cho \(\mathsf{SBox}\)) giống với xác suất cao nhất với phân tích \(\mathsf{SBox}\) ở trên kia.
1.2.3. Chosen plaintext¶
Differential attack là một dạng chosen plaintext, trong đó chúng ta tận dụng các xác suất ở trên.
1.2.3.1. Chosen plaintext phần một¶
Do tính chất vi sai, chúng ta sẽ mong muốn tìm những cặp (plaintext, ciphertext) \((P_1, C_1)\) và \((P_2, C_2)\) nào đó mà vi sai input \(P_1 \oplus P_2\) và vi sai output \(C_1 \oplus C_2\) có thể tối ưu xác suất trên.
Giả sử chúng ta xét trường hợp 3 ở trên, khi vi sai input của \(F\) là \(3\) thì vi sai output của \(F\) là \(8\) với xác suất \(1/4\). Đây là xác suất lớn nhất nên ta mong muốn trong 3 vòng của TinyDES sẽ tận dụng được càng nhiều càng tốt.
Chúng ta đi từ dưới lên. Đặt
và
Chọn \(R_2 \oplus R_2' = 3\) thì \(F(R_2, K_3) \oplus F(R_2', K_3) = 8\) với xác suất \(1/4\). Vì là bước cuối nên ta hy vọng ciphertext cuối cùng sẽ càng ít phức tạp càng tốt. Do đó có thể lựa chọn \(L_2 = L_2' = 0\) để bảo toàn vi sai sau khi vòng 3 kết thúc.
Ở vòng 3, xác suất để vi sai input bằng \(3\) và vi sai output bằng \(8\) là \(1/4\).
Tiếp theo, đặt:
và
Do \(L_2 = R_1\) nên \(R_1 = 0\). Tương tự \(R_1' = L_2' = 0\). Điều đáng chú ý là \(R_1 \oplus R_1' = 0\), nghĩa là vi sai input bằng \(0\), nên vi sai output \(F(R_1, K_2) \oplus F(R_1', K_2)\) chắc chắn bằng \(0\) (xác suất bằng \(1\)).
Ở vòng 2, xác suất để vi sai input bằng \(0\) và vi sai output bằng \(0\) là \(1\).
Ta lại có
do vi sai output hàm \(F\) chắc chắn bằng \(0\). Do đó \(L_1 \oplus L_1' = 3\).
Tuy nhiên, \(L_1 = R_0\) và \(L_1' = R_0'\) nên \(L_1 \oplus L_1' = R_0 \oplus R_0' = 3\). Do đó vi sai output của hàm \(F\) là \(F(R_0, K_1) \oplus F(R_0', K_1) = 8\) có xác suất \(1/4\).
Ở vòng 1, xác suất để vi sai input bằng \(3\) và vi sai output bằng \(8\) là \(1/4\).
Cuối cùng,
mà ta nhớ lại ở trên \(R_1 \oplus R_1' = 0\) nên suy ra \(L_0 \oplus L_0' = 8\).
Tổng kết lại, ta chọn vi sai input \((L, R) = (8, 3)\) thì xác suất để vi sai output bằng \((3, 8)\) là \((1/4) \times 1 \times (1/4) = 1/16\). Đây là xác suất cao nhất có thể sau khi TinyDES chạy đủ 3 vòng.
1.2.3.2. Chosen plaintext phần hai¶
Tương tự, chúng ta xét trường hợp 2 ở trên, khi vi sai input của \(F\) là \(1\) thì vi sai output của \(F\) là \(11\) với xác suất \(7/32\). Ta cũng mong muốn sau 3 vòng của TinyDES sẽ tận dụng được càng nhiều càng tốt.
Chúng ta lại đi dưới lên. Đặt
và
Chọn \(R_2 \oplus R_2' = 1\) thì \(F(R_2, K_3) \oplus F(R_2', K_3) = 11\) với xác suất \(7/32\). Vì là bước cuối cùng nên ta cũng hy vọng ciphertext sẽ càng ít phức tạp càng tốt. Do đó ta chọn \(L_2 = L_2' = 0\).
Ở vòng 3, xác suất để vi sai input bằng \(1\) và vi sai output bằng \(11\) là \(7/32\).
Tiếp theo, đặt
và
Do \(L_2 = R_1\) nên \(R_1 = 0\). Tương tự \(R_1' = 0\). Suy ra \(R_1 \oplus R_1' = 0\) và vi sai output \(F(R_1, K_2) \oplus F(R_1', K_2) = 0\) với xác suất bằng \(1\) (chắc chắn xảy ra).
Ở vòng 2, xác suất để vi sai input bằng \(0\) và vi sai output bằng \(0\) là \(1\).
Ta lại có:
do vi sai output của hàm \(F\) chắc chắn bằng \(0\). Do đó \(L_1 \oplus L_1' = 1\).
Tuy nhiên \(L_1 = R_0\) và \(L_1' = R_0'\) nên \(R_0 \oplus R_0' = L_1 \oplus L_1' = 1\). Do đó vi sai output của hàm \(F\) ở vòng \(1\) là \(F(R_0, K_1) \oplus F(R_0', K_1) = 11\) với xác suất \(7/32\).
Ở vòng 1, xác suất để vi sai input bằng \(1\) và vi sai output bằng \(11\) là \(7/32\).
Cuối cùng, do
mà \(R_1 \oplus R_1' = 0\) và \(F(R_0, K_1) \oplus F(R_0', K_1) = 11\) nên \(L_0 \oplus L_0' = 11\).
Tổng kết lại, ta chọn vi sai input \((L, R) = (11, 1)\) thì xác suất để vi sai output bằng \((1, 11)\) là \((7/32) \times 1 \times (7/32) \approx 0.048\). Đây cũng là xác suất cao nhất có thể sau khi TinyDES chạy đủ 3 vòng.
1.2.3.3. Final attack¶
Như vậy, đối với TinyDES chúng ta phá mã vi sai như sau:
Tìm một số lượng cặp plaintext, ciphertext \((P_1, C_1)\), \((P_2, C_2)\), ... cho tới khi tìm được \(P_i \oplus P_j = \mathrm{0x83}\) và \(C_i \oplus C_j = \mathrm{0x38}\).
Tìm một số lượng cặp plaintext, ciphertext \((P_1', C_1')\), \((P_2', C_2')\), ... cho tới khi tìm được \(P_i' \oplus P_j' = \mathrm{0xB1}\) và \(C_i' \oplus C_j' = \mathrm{0x1B}\).
Sau khi đã tìm được một số lượng cặp plaintext, ciphertext thỏa vi sai trên, nhớ lại hàm \(F\) ở vòng 3, do
theo cách chọn \(L_2 = 0\) ở trên, dễ thấy rằng chúng ta có thể tìm được các \(K_3\) thỏa mãn hàm \(F\) ở vòng 3.
Để làm điều đó thì ta tính \(O = \mathsf{Expand}(L_3)\), và do \(\mathsf{SBox}(O \oplus K_3) = \mathsf{PBox}^{-1}(R_3)\) cũng tính được nên có thể tìm các giá trị \(O \oplus K_3\) mà khi đi qua \(\mathsf{SBox}\) cho kết quả bằng \(\mathsf{PBox}^{-1}(R_3)\). Sau đó XOR lại cho \(O\) thì sẽ tìm được các giá trị có thể của \(K_3\). Lưu ý rằng \(\mathsf{SBox}\) làm giảm \(6\) bits còn \(4\) bits nên sẽ có nhiều giá trị khác nhau cho cùng giá trị \(\mathsf{SBox}\).
Thực hiện trên hai trường hợp vi sai input-output là \((\mathrm{0x83}, \mathrm{0x38})\) và \((\mathrm{0xB1}, \mathrm{0x1B})\) ta có tập các giá trị có thể xảy ra của \(K_3\).
Theo thuật toán sinh khóa con thì với khóa \(K\) \(8\) bits ban đầu, đặt là \(k_0 k_1 k_2 k_3 k_4 k_5 k_6 k_7\), thì khóa con \(K_3\) là \(k_5 k_1 k_3 k_2 k_7 k_0\). Trong \(K_3\) không có \(k_4\) và \(k_6\) nên chúng ta sẽ bruteforce hai bit này tới khi tìm được đúng khóa \(K\) mà tương ứng với cặp \((P_i, C_i)\).
find_key.py
# find_key.py
import tinydes
from itertools import product
def int_to_vec6(n: int) -> list[int]:
return list(map(int, format(n, "06b")))
def int_to_vec8(n: int) -> list[int]:
return list(map(int, format(n, "08b")))
def vec_to_int(v: list[int]) -> int:
return int("".join(map(str, v)), 2)
def recover_key(k: list[int]) -> list[int]:
return [k[5], k[1], k[3], k[2], 0, k[0], 0, k[4]]
key = [1, 0, 0, 1, 1, 0, 1, 0]
ptx = []
ctx = []
pt, ct = [0, 1, 0, 1, 1, 1, 0, 0], [1, 0, 0, 1, 1, 0, 1, 0]
candidates = []
K3 = []
for _ in range(24):
pt = int_to_vec8(_)
ct = tinydes.encrypt_block(pt, key)
pt_ = tinydes.Xor(int_to_vec8(0x83), pt)
ct_ = tinydes.encrypt_block(pt_, key)
if tinydes.Xor(ct_, ct) == list(map(int, format(0x38, "08b"))):
ptx.append(pt_)
ctx.append(ct_)
candidates.append((pt, pt_))
break
for pt1, pt2 in candidates:
o1, o2 = tinydes.PBox_inv(pt1[4:]), tinydes.PBox_inv(pt2[4:])
q1, q2 = tinydes.Expand(pt1[:4]), tinydes.Expand(pt2[:4])
for i in range(len(tinydes.sbox)):
if tinydes.sbox[i] == vec_to_int(o1):
row, col = i // 16, i % 16
idx = [row // 2] + list(map(int, format(col, "04b"))) + [row % 2]
K3.append(tinydes.Xor(q1, idx))
if tinydes.sbox[i] == vec_to_int(o2):
row, col = i // 16, i % 16
idx = [row // 2] + list(map(int, format(col, "04b"))) + [row % 2]
K3.append(tinydes.Xor(q2, idx))
candidates = []
for _ in range(24):
pt = int_to_vec8(_)
ct = tinydes.encrypt_block(pt, key)
pt_ = tinydes.Xor(int_to_vec8(0xb1), pt)
ct_ = tinydes.encrypt_block(pt_, key)
if tinydes.Xor(ct_, ct) == list(map(int, format(0x1b, "08b"))):
ptx.append(pt_)
ctx.append(ct_)
candidates.append((pt, pt_))
break
for pt1, pt2 in candidates:
o1, o2 = tinydes.PBox_inv(pt1[4:]), tinydes.PBox_inv(pt2[4:])
q1, q2 = tinydes.Expand(pt1[:4]), tinydes.Expand(pt2[:4])
for i in range(len(tinydes.sbox)):
if tinydes.sbox[i] == vec_to_int(o1):
row, col = i // 16, i % 16
idx = [row // 2] + list(map(int, format(col, "04b"))) + [row % 2]
K3.append(tinydes.Xor(q1, idx))
if tinydes.sbox[i] == vec_to_int(o2):
row, col = i // 16, i % 16
idx = [row // 2] + list(map(int, format(col, "04b"))) + [row % 2]
K3.append(tinydes.Xor(q2, idx))
for k3 in set([vec_to_int(k) for k in K3]):
k = recover_key(int_to_vec6(k3))
for k4, k6 in product(range(2), repeat=2):
k[4], k[6] = k4, k6
if tinydes.encrypt_block(pt, k) == ct:
print(f"Recover key: {k}")