NSUCRYPTO 2024¶
Trong hai bài viết mình sẽ giới thiệu cách giải các bài trong NSUCRYPTO 2024 từ bài giải của team mình lẫn từ team các bạn mà mình tham khảo sau khi kết thúc giải. Hiện tại chỉ có team của Robin Jadoul, Jack Pope, Esrever Yievs chia sẻ bài giải gần hoàn chỉnh trên discord của một cộng đồng toxic nào đó mà ai cũng biết nên mình sẽ gọi là team JPY khi đề cập tới cách giải của các bạn (lấy chữ cái đầu họ của ba người :v).
Lời nói đầu¶
Đầu tiên mình xin cám ơn rất nhiều người đã ủng hộ, giúp đỡ mình trong mấy năm qua, để mình có thể đi tới ngày hôm nay.
Đề thi năm nay khiến mình có chút hoang mang khi bắt đầu làm. Round 2 có 11 câu với hai câu special prize. Thường những năm trước có từ 4 tới 5 câu special prize và đây là nơi đột biến xảy ra. Nếu chỉ có hai câu thì mình không hy vọng được giải cao mà mục tiêu là giải trọn vẹn và không mắc lỗi ở tất cả câu khác.
Và điều kì diệu đã xảy ra :))) team mình được hai bài BEST SOLUTION do hai bạn teammate giải, còn mình thì ... ké :D
Chân thành cám ơn bạn Chương và bạn Uyên đã đồng hành cũng mình hai năm nay.
RSA signature¶
Đây là bài 7 ở round 1 và bài 1 ở round 2.
Đề bài¶
Chúng ta cần ký thông điệp \(M\) bằng thuật toán RSA. Như bình thường, đặt \(N = p \cdot q\) là RSA-modulus với \(p\) và \(q\) là hai số nguyên tố lớn.
Đặt \(e\) là public exponent và \(d\) là secret exponent với
Signature của chúng ta sẽ là
Giả sử kẻ tấn công biết giá trị
nhưng không biết giá trị
trong đó
Nếu kẻ tấn công biết modulo \(N\) (nhưng không biết \(p\) và \(q\)), biết public exponent \(e\) (nhưng không biết \(d\)) và biết thông điệp gốc \(M\). Các thông số bí mật nào kẻ tấn công có thể tìm ra?
Lời giải¶
Vì \(S \equiv M^d \pmod N\) nên suy ra \(S \equiv M^d \pmod p\) vì
tương tự \(S \equiv M^d \pmod q\).
Ngoài ra ta có
Tương tự phía trên ta cũng có
nhưng \(d_p \equiv d \pmod{p-1}\), tương đương với
với \(k_p \in \mathbb{Z}\).
Do đó
Từ hai phương trình (9) và (10) suy ra
hay ta có thể nói là
Từ đây, sử dụng thuật toán Euclid ta tìm được
Vậy là ta đã tìm được \(p\) nên có thể tìm được tất cả tham số secret khác của RSA là \(q\), \(d\), \(d_p\) và \(d_q\).
solve.py
from Crypto.Util.number import getPrime
import random
def gcd(a, b):
while b:
a, b = b, a % b
return a
p, q = [getPrime(1024) for _ in range(2)]
print(f"{p = }")
print(f"{q = }")
e = 65537
N = p * q
d = pow(e, -1, (p - 1) * (q - 1))
M = random.randint(1, N - 1)
dp = d % (p - 1)
Mp = pow(M, dp, p)
print(f"{N = }")
print(f"{e = }")
print(f"{M = }")
print(f"{Mp = }")
p_guess = gcd(pow(Mp, e, N) - M, N)
assert p == p_guess
print("Successfully recoverd p")
AntCipher 2.0¶
Đây là bài 2 ở round 2.
Đề bài¶
Một phút một lần, GPS được track bởi vệ tinh. Khi đó, vĩ độ ở dạng IEEE 754 single-precision floating-point sẽ được chuyển thành dãy 32 bit. Tương tự cho kinh độ.
Khi đó hai dãy nhị phân sẽ được nối lại (lattile || longitude) thành plaintext có 64 bit. Sau đó plaintext được XOR với keystream để tạo thành ciphertext 64 bit.
Cách thực hiện sinh khóa như sau. Tại điểm khởi tạo, secret key 64 bit được viết vào thanh ghi \(R\) dung lượng 64 bit.
Với mỗi số \(i\) với \(i \geqslant 1\), dãy \(K_i\) 64 bit sẽ được sinh từ input là \(R\) và keystream cũng dùng để cập nhật thanh ghi \(R\), nghĩa là sau khi tính toán thì giá trị \(K_i\) sẽ được ghi vào \(R\).
Xét dạng CNF của hàm \(C\), với CNF là conjunction of disjunction (tích của các tổng), có dạng sau:
Phương trình \(C = 1\) biểu diễn một hàm không tuyến tính \(F_G\) lấy đầu vào là \(4\) bits \((x_1, x_2, x_3, x_4)\) và sinh ra \(4\) bits \((x_5, x_6, x_7, x_8)\) làm output.
Ở vòng lặp thứ \(i\) của cipher, \(64\) bits của \(R\) được chia thành \(16\) đoạn, mỗi đoạn \(4\) bit. Mỗi đoạn thành input cho \(F_G\) và kết quả là \(16\) đoạn \(4\) bits mới được nối với nhau thành \(K_i\) có \(64\) bits.
\(1704\) ciphertexts được truyền đi không gặp vấn đề. Tuy nhiên ở hai keystream tiếp theo gặp sự cố về đĩa cứng nên chỉ nhận được ciphertext thứ \(1704\) là dãy
1001 1000 0011 1101 0110 0011 1101 0101 1011 0011 1011 0111 0000 0000 1000 0011
và hai keystrem \(1702\) và \(1703\) nhưng bị mất một phần:
Hãy tìm lại plaintext thứ \(1704\).
Lời giải¶
Đầu tiên mình cần tìm những bộ số \((x_1, \ldots, x_8)\) mà \(C = 1\).
from itertools import product
def f(x1, x2, x3, x4, x5, x6, x7, x8):
result = 1
result = result & (x1 | x2 | ~x5)
result = result & (~x1 | ~x2 | x5)
result = result & (x1 | x3 | ~x5)
result = result & (~x1 | ~x3 | x5)
result = result & (x2 | x3 | ~x5)
result = result & (~x2 | ~x3 | x5)
result = result & (x1 | x2 | ~x6)
result = result & (~x1 | ~x2 | x6)
result = result & (x1 | x4 | ~x6)
result = result & (~x1 | ~x4 | x6)
result = result & (x2 | x4 | ~x6)
result = result & (~x2 | ~x4 | x6)
result = result & (x1 | x3 | ~x7)
result = result & (~x1 | ~x3 | x7)
result = result & (x1 | x4 | ~x7)
result = result & (~x1 | ~x4 | x7)
result = result & (x3 | x4 | ~x7)
result = result & (~x3 | ~x4 | x7)
result = result & (x2 | x3 | ~x8)
result = result & (~x2 | ~x3 | x8)
result = result & (x2 | x4 | ~x8)
result = result & (~x2 | ~x4 | x8)
result = result & (x3 | x4 | ~x8)
result = result & (~x3 | ~x4 | x8)
return result
key = { }
for x1, x2, x3, x4, x5, x6, x7, x8 in product(range(2), repeat=8):
t = f(x1, x2, x3, x4, x5, x6, x7, x8)
if t == 1:
print(f"{x1, x2, x3, x4} -> {x5, x6, x7, x8}")
a = x1 + (x2 << 1) + (x3 << 2) + (x4 << 3)
b = x5 + (x6 << 1) + (x7 << 2) + (x8 << 3)
key[a] = b
Bảng biến đổi sẽ như sau:
\((x_1, x_2, x_3, x_4)\) |
\(\rightarrow\) |
\((x_5, x_6, x_7, x_8)\) |
|---|---|---|
\((0, 0, 0, 0)\) |
\(\rightarrow\) |
\((0, 0, 0, 0)\) |
\((0, 0, 0, 1)\) |
\(\rightarrow\) |
\((0, 0, 0, 0)\) |
\((0, 0, 1, 0)\) |
\(\rightarrow\) |
\((0, 0, 0, 0)\) |
\((0, 0, 1, 1)\) |
\(\rightarrow\) |
\((0, 0, 1, 1)\) |
\((0, 1, 0, 0)\) |
\(\rightarrow\) |
\((0, 0, 0, 0)\) |
\((0, 1, 0, 1)\) |
\(\rightarrow\) |
\((0, 1, 0, 1)\) |
\((0, 1, 1, 0)\) |
\(\rightarrow\) |
\((1, 0, 0, 1)\) |
\((0, 1, 1, 1)\) |
\(\rightarrow\) |
\((1, 1, 1, 1)\) |
\((1, 0, 0, 0)\) |
\(\rightarrow\) |
\((0, 0, 0, 0)\) |
\((1, 0, 0, 1)\) |
\(\rightarrow\) |
\((0, 1, 1, 0)\) |
\((1, 0, 1, 0)\) |
\(\rightarrow\) |
\((1, 0, 1, 0)\) |
\((1, 0, 1, 1)\) |
\(\rightarrow\) |
\((1, 1, 1, 1)\) |
\((1, 1, 0, 0)\) |
\(\rightarrow\) |
\((1, 1, 0, 0)\) |
\((1, 1, 0, 1)\) |
\(\rightarrow\) |
\((1, 1, 1, 1)\) |
\((1, 1, 1, 0)\) |
\(\rightarrow\) |
\((1, 1, 1, 1)\) |
\((1, 1, 1, 1)\) |
\(\rightarrow\) |
\((1, 1, 1, 1)\) |
Có thể thấy đầu ra không chứa đủ \(16\) trường hợp mà chỉ gồm các trường hợp là
Ở đây mỗi vector đều có số lượng chẵn phần tử \(1\).
Xét biến đổi từ \(K_{1702}\) thành \(K_{1703}\) như sau:
\(K_{1702}\) |
\(\rightarrow\) |
\(K_{1703}\) |
|---|---|---|
\(\text{0101}\) |
\(\rightarrow\) |
\(\text{XXXX}\) |
\(\text{1001}\) |
\(\rightarrow\) |
\(\text{XXXX}\) |
\(\text{1111}\) |
\(\rightarrow\) |
\(\text{XXXX}\) |
\(\text{0011}\) |
\(\rightarrow\) |
\(\text{XXXX}\) |
\(\text{00X1}\) |
\(\rightarrow\) |
\(\text{XXXX}\) |
\(\text{X111}\) |
\(\rightarrow\) |
\(\text{XXXX}\) |
\(\text{1X00}\) |
\(\rightarrow\) |
\(\text{XXXX}\) |
\(\text{00X0}\) |
\(\rightarrow\) |
\(\text{XXXX}\) |
\(\text{111X}\) |
\(\rightarrow\) |
\(\text{X111}\) |
\(\text{X000}\) |
\(\rightarrow\) |
\(\text{000X}\) |
\(\text{XXXX}\) |
\(\rightarrow\) |
\(\text{X010}\) |
\(\text{XXXX}\) |
\(\rightarrow\) |
\(\text{01X1}\) |
\(\text{XXXX}\) |
\(\rightarrow\) |
\(\text{0X10}\) |
\(\text{XXXX}\) |
\(\rightarrow\) |
\(\text{0101}\) |
\(\text{XXXX}\) |
\(\rightarrow\) |
\(\text{0000}\) |
\(\text{XXXX}\) |
\(\rightarrow\) |
\(\text{1111}\) |
Dựa vào bảng biến đổi ở trên và lưu ý đầu ra (có \(8\) trường hợp tất cả) thì ta có kết luận cho từng bộ \(4\) như sau:
\(0101 \rightarrow 010\).
\(1001 \rightarrow 0110\).
\(1111 \rightarrow 1111\).
\(0011 \rightarrow 0011\).
\(\text{00X1} \rightarrow 0000\). Vì \(K_{1702}\) nhận được từ \(K_{1701}\) nên X chỉ có thể là \(1\) và kết quả ở \(K_{1703}\) sẽ là \(0000\).
\(\text{X111} \rightarrow 1111\).
\(\text{1X00} \rightarrow 0000\). Tương tự, vì \(K_{1702}\) nhận được từ \(K_{1701}\) nên X chỉ có thể là \(1\) và kết quả ở \(K_{1703}\) là \(0000\).
\(\text{0X00} \rightarrow 0000\).
\(\text{111X} \rightarrow 1111\).
\(\text{X000} \rightarrow 0000\).
\(\text{XXXX} \rightarrow 1010\). Trong mỗi bộ số trong \(8\) trường hợp ở trên thì số lượng chữ số \(1\) là chẵn.
\(\text{XXXX} \rightarrow 0101\). Tương tự.
\(\text{XXXX} \rightarrow 0110\). Tương tự
\(\text{XXXX} \rightarrow 0101\).
\(\text{XXXX} \rightarrow 0000\).
\(\text{XXXX} \rightarrow 1111\).
Như vậy mình đã khôi phục được \(K_{1703}\) và có thể decrypt.
# https://gist.github.com/AlexEshoo/d3edc53129ed010b0a5b693b88c7e0b5
def ieee_754_conversion(n, sgn_len=1, exp_len=8, mant_len=23):
"""
Converts an arbitrary precision Floating Point number.
Note: Since the calculations made by python inherently use floats, the accuracy is poor at high precision.
:param n: An unsigned integer of length `sgn_len` + `exp_len` + `mant_len` to be decoded as a float
:param sgn_len: number of sign bits
:param exp_len: number of exponent bits
:param mant_len: number of mantissa bits
:return: IEEE 754 Floating Point representation of the number `n`
"""
if n >= 2 ** (sgn_len + exp_len + mant_len):
raise ValueError("Number n is longer than prescribed parameters allows")
sign = (n & (2 ** sgn_len - 1) * (2 ** (exp_len + mant_len))) >> (exp_len + mant_len)
exponent_raw = (n & ((2 ** exp_len - 1) * (2 ** mant_len))) >> mant_len
mantissa = n & (2 ** mant_len - 1)
sign_mult = 1
if sign == 1:
sign_mult = -1
if exponent_raw == 2 ** exp_len - 1: # Could be Inf or NaN
if mantissa == 2 ** mant_len - 1:
return float('nan') # NaN
return sign_mult * float('inf') # Inf
exponent = exponent_raw - (2 ** (exp_len - 1) - 1)
if exponent_raw == 0:
mant_mult = 0 # Gradual Underflow
else:
mant_mult = 1
for b in range(mant_len - 1, -1, -1):
if mantissa & (2 ** b):
mant_mult += 1 / (2 ** (mant_len - b))
return sign_mult * (2 ** exponent) * mant_mult
ciphertext = "1001 1000 0011 1101 0110 0011 1101 0101 1011 0011 1011 0111 0000 0000 1000 0011"
ciphertext = list(map(int, "".join(ciphertext.split(" "))))
keystream = "0101 0110 1111 0011 0011 1111 1100 0000 1111 0000 1010 0101 0110 0101 0000 1111"
keystream = [int(i, 2) for i in keystream.split(" ")]
keystream = [key[k] for k in keystream] # Find K_{1704} from K_{1703} by table 1
keystream = "".join(f"{k:04b}" for k in keystream)
keystream = list(map(int, keystream))
plaintext = [c^k for c, k in zip(ciphertext, keystream)] # Recover plaintext
plaintext = "".join(map(str, plaintext))
assert len(plaintext) == 64
m, n = int(plaintext[:32], 2), int(plaintext[32:], 2) # Extract first 32 bits and last 32 bits
latitude = ieee_754_conversion(m) # Convert first 32 bits to latitude
longitude = ieee_754_conversion(n) # Convert last 32 bits to longitude
print(f"({latitude}, {longitude})")
Mình nhận được tọa độ là
Tọa độ này chỉ tới Australia (Augathella), cụ thể là một công viên tên là "Meat Ant Park". Chữ "Ant" có vẻ khớp với đề bài.
Steganography and codes¶
Đây là bài 3 ở round 2.
Đề bài¶
Sam và Betty sử dụng kênh mở cho giao tiếp bí mật. Họ không muốn ai biết về hội thoại của mình.
Sam có thể gửi co Betty một trong \(16\) thông điệp.
Khi đó, Sam lấy một ảnh với format RGB bất kì, đổi pixel đầu tiên theo cách nào đó và publish lên website.
Betty sẽ tải bức ảnh đó xuống và phân tích xem Sam đã gửi thông điệp nào.
Sam sẽ làm gì với bức ảnh? Chúng ta nên chú ý rằng phải thay đổi pixel sao cho không thể nhận biết sự thay đổi bởi mắt thường.
Cụ thể, mỗi pixel RGB được biểu diễn ở dạng \(24\) bit:
\(8\) bit đầu là độ sáng của màu đỏ \((r_1, \ldots, r_8)\);
\(8\) bit tiếp theo là độ sáng màu xanh lá \((g_1, \ldots, g_8)\);
\(8\) bit cuối là độ sáng màu xanh dương \((b_1, \ldots, b_8)\).
Sam không được thay đổi các bit \(r\), \(g\), \(b\) từ \(1\) tới \(5\) vì điều đó sẽ dễ nhận thấy khi nhìn bằng mắt.
Nếu Sam đổi một trong các bit \(r_6\), \(r_7\), \(g_6\), \(g_7\) và \(b_6\) sẽ tốn \(2\) coins mỗi lần đổi.
Nếu Sam đổi một trong các bit \(r_8\), \(g_8\), \(b_7\) và \(b_8\) thì tốn \(1\) coin mỗi lần đổi.
Hãy đưa ra một phương pháp coding cho \(16\) thông điệp vào một pixel mà tốn không quá \(2\) coins (mà không thể nhận thấy bằng mắt thường).
Thêm nữa hãy đưa ra một phương để Betty có thể biết được thông điệp mà Sam giấu vào ảnh là gì. Lưu ý rằng Betty không biết ảnh gốc như thế nào.
Lời giải¶
Tạm thời trống.
Weak key schedule for DES¶
Đây là bài 6 ở round 1 và bài 4 ở round 2.
Đề bài¶
Alice sử dụng thuật toán DES để mã hóa file Book.txt thành Book_Cipher.txt. Tuy nhiên khi code thuật toán DES thì Alice đã code lỗi và khiến cả thuật toán chỉ sử dụng subkey đầu tiên cho tất cả các vòng (thay vì mỗi vòng mỗi khóa con như DES chuẩn).
Hãy giúp Carol tìm lại khóa ban đầu và decrypt bản mã sau:
86991641D28259604412D6BA88A5C0A6471CA722
2C52482BF2D0E841D4343DFB877DC8E0147F3D5F
20FC18FF28CB5C4DA8A0F4694861AB5E98F37ADB
C2D69B35779D9001BB4B648518FE6EBC00B2AB10
Lời giải¶
Bài này được giải bởi bạn Chương và được thêm BEST SOLUTION :)))
Ý tưởng của bài này là slide attack. Các bạn có thể xem lời giải ở bài viết về slide attack của mình.
Reverse engineering¶
Đây là bài 5 ở round 2.
Đề bài¶
Sau khi reverse engineering cài đặt của một thuật toán mật mã nào đó chưa biết thì Bob nhận được hàm boolean sau:
Bob cố gắng hiểu ý nghĩa mật mã của hàm boolean trên là gì, và nhanh chóng tìm thấy một "liên hệ". Đây là hàm gì?
Mở đầu¶
Bài này mình chứng minh được tính chất của hàm đề bài cho chứ không tìm ra ý nghĩa của hàm nên chỉ được 4/6 điểm.
Tham khảo lời giải của team JPY thì đây là hàm kiểm tra tràn bit số nguyên (integer overflow).
Mình sẽ trình bày cả cách giải của mình lẫn cách giải của team bạn.
Hình đề cho là CAST cipher - tiêu chuẩn mã hóa của Canada.
S-boxes trong CAST cipher được lựa chọn từ các hàm boolean có nonlinearity cao nhất nên trong lúc làm bài mình cắm đầu vào tìm một tính chất gì đó của hàm boolean trên liên quan tới nonlinearity.
Mình đã chứng minh được hai điều:
trọng số Hamming của hàm \(f_{2n}\) bằng \(2^{n-1} \cdot (2^n - 1)\);
nonlinearity của hàm \(f_{2n}\) bằng \(2^{2n-2}\).
Nhắc lại hàm boolean \(f_{2n}\) đề cho là hàm
Trọng số Hamming của hàm boolean¶
Để tìm công thức hoặc tính chất thì thường mình sẽ thử với các số nhỏ và sau đó đoán công thức.
Với \(n = 1\) thì \(f_2(x_1, x_2) = x_1 x_2\). Dễ thấy rằng \(f_2 = 1\) khi \(x_1 = x_2 = 1\).
Thay vì viết bảng chân trị gồm \(4\) dòng thì mình viết thành bảng ô vuông \(2 \times 2\):
\(x_2 = 0\) |
\(x_2 = 1\) |
|
\(x_1 = 0\) |
\(f_2 = 0\) |
\(f_2 = 0\) |
\(x_1 = 1\) |
\(f_2 = 0\) |
\(f_2 = {\color{red}1}\) |
Với \(n = 2\) thì hàm boolean là
Cũng tương tự, mình viết bảng chân trị thành bảng ô vuông \(4 \times 4\):
\(x_3 x_4 = 00\) |
\(x_3 x_4 = 01\) |
\(x_3 x_4 = 10\) |
\(x_3 x_4 = 11\) |
|
\(x_1 x_2 = 00\) |
\(f_4 = 0\) |
\(f_4 = 0\) |
\(f_4 = 0\) |
\(f_4 = 0\) |
\(x_1 x_2 = 01\) |
\(f_4 = 0\) |
\(f_4 = 0\) |
\(f_4 = 0\) |
\(f_4 = {\color{red}1}\) |
\(x_1 x_2 = 10\) |
\(f_4 = 0\) |
\(f_4 = 0\) |
\(f_4 = {\color{red}1}\) |
\(f_4 = {\color{red}1}\) |
\(x_1 x_2 = 11\) |
\(f_4 = 0\) |
\(f_4 = {\color{red}1}\) |
\(f_4 = {\color{red}1}\) |
\(f_4 = {\color{red}1}\) |
Với \(n = 3\) thì mình viết bảng chân trị thành bảng \(8 \times 8\):
\(000\) |
\(001\) |
\(010\) |
\(011\) |
\(100\) |
\(101\) |
\(110\) |
\(111\) |
|
\(000\) |
\(0\) |
\(0\) |
\(0\) |
\(0\) |
\(0\) |
\(0\) |
\(0\) |
\(0\) |
\(001\) |
\(0\) |
\(0\) |
\(0\) |
\(0\) |
\(0\) |
\(0\) |
\(0\) |
\({\color{red}1}\) |
\(010\) |
\(0\) |
\(0\) |
\(0\) |
\(0\) |
\(0\) |
\(0\) |
\({\color{red}1}\) |
\({\color{red}1}\) |
\(011\) |
\(0\) |
\(0\) |
\(0\) |
\(0\) |
\(0\) |
\({\color{red}1}\) |
\({\color{red}1}\) |
\({\color{red}1}\) |
\(100\) |
\(0\) |
\(0\) |
\(0\) |
\(0\) |
\({\color{red}1}\) |
\({\color{red}1}\) |
\({\color{red}1}\) |
\({\color{red}1}\) |
\(101\) |
\(0\) |
\(0\) |
\(0\) |
\({\color{red}1}\) |
\({\color{red}1}\) |
\({\color{red}1}\) |
\({\color{red}1}\) |
\({\color{red}1}\) |
\(110\) |
\(0\) |
\(0\) |
\({\color{red}1}\) |
\({\color{red}1}\) |
\({\color{red}1}\) |
\({\color{red}1}\) |
\({\color{red}1}\) |
\({\color{red}1}\) |
\(111\) |
\(0\) |
\({\color{red}1}\) |
\({\color{red}1}\) |
\({\color{red}1}\) |
\({\color{red}1}\) |
\({\color{red}1}\) |
\({\color{red}1}\) |
\({\color{red}1}\) |
Đến đây thì mình nhận thấy hàm \(f_{2n}\) sẽ nhận giá trị \(1\) tại:
\(1\) ô hàng thứ hai;
\(2\) ô hàng thứ ba;
...
\(2^n-1\) ô hàng cuối.
Như vậy trọng số Hamming được dự đoán là
Sau đây mình sẽ chứng minh công thức trọng số Hamming này bằng quy nạp.
Với \(n = 1\), hàm \(f_2(x_1, x_2) = x_1 x_2\) có trọng số Hamming là \(1 = 2^{1-1} \cdot (2^1 - 1)\). Như vậy công thức đúng với \(n = 1\).
Giả sử công thức đúng với \(n = k \geqslant 1\), nghĩa là hàm
có trọng số Hamming là \(2^{k-1} \cdot (2^k - 1)\).
Với \(n = k + 1\), xét hàm
Ta có các trường hợp sau:
khi \(y = z = 0\) thì \(y \oplus z = 0\) và \(yz = 0\). Khi đó mọi phép nhân \(\prod\limits_{j=i+1}^k (x_j \oplus x_{j+k}) \cdot (y \oplus z) = 0\) nên khiến cả hàm \(f_{2k+2} = 0\) tại tất cả vector \((x_1, \ldots, x_{2k})\);
khi \(y = 0\) và \(z = 1\) thì \(y \oplus z = 1\) và \(yz = 0\). Thay vào hàm \(f_{2k+2}\) ta có
Như vậy khi \(y = 0\) và \(z = 1\) thì \(f_{2k+2}\) chính xác bằng \(f_{2k}\). Nghĩa là trọng số Hamming của \(f_{2k+2}\) lúc này bằng trọng số Hamming của \(f_{2k}\) và bằng \(2^{k-1} \cdot (2^k - 1)\) theo giả thiết quy nạp.
khi \(y = 1\) và \(z = 0\) thì tương tự, trọng số Hamming của \(f_{2k+2}\) trong trường hợp này cũng bằng \(2^{k-1} \cdot (2^k - 1)\).
khi \(y = z = 1\) thì \(y \oplus z = 0\) và \(yz = 1\). Khi đó tất cả biểu thức \(\prod\limits_{j=i+1}^k (x_j \oplus x_{j+k}) \cdot (y \oplus z) = 0\) nên hàm \(f_{2k+2} = 1\) với mọi đầu vào \((x_1, \ldots, x_{2k}) \in \mathbb{F}_2^{2k}\). Như vậy trọng số Hamming của \(f_{2k+2}\) ở trường hợp này là \(2^{2k}\).
Kết hợp bốn trường hợp lại thì trọng số Hamming của \(f_{2k+2}\) là
Như vậy công thức trọng số Hamming đúng với \(k + 1\) nên theo quy nạp thì công thức đúng với mọi \(n \geqslant 1\).
Biến đổi Walsh-Hadamard và nonlinearity¶
Gọi \(W_f(\bm{a})\) là hệ số Walsh của hàm boolean \(f\) (trên \(2n\) biến) ứng với vector \(\bm{a} \in \mathbb{F}_2^{2n}\).
Đặt \(\bm{0}\) là vector độ dài \(2n\) chỉ gồm các số \(0\), nghĩa là \(\bm{0} = (0, \ldots, 0)\).
Một tính chất đơn giản của phổ Walsh là
với \(f\) là hàm boolean \(2n\) biến.
Từ kết quả về trọng số ở trên, thay vào công thức ta có
Bây giờ xét hệ số Walsh cho vector dạng
Công thức tính hệ số Walsh là
Nếu \(a_n = a_{2n} = 0\) thì ta có trường hợp \(W_f(\bm{0})\) như vừa rồi.
Nếu \(a_n = 1\) và \(a_{2n} = 0\) ta sẽ chứng minh hệ số Walsh lúc này có giá trị tuyệt đối lớn nhất. Tương tự đối với \(a_n = 0\) và \(a_{2n} = 1\) cũng sẽ cho hệ số Walsh có giá trị tuyệt đối lớn nhất.
Khi \(a_n = 1\) và \(a_{2n} = 0\) thì hệ số Walsh sẽ có dạng
ở đây \(\bm{x} = (x_1, \ldots, x_{2n})\).
Ta có hai trường hợp:
Trường hợp 1. Nếu \(x_n = 0\) thì trong số \(2^{2n-1}\) vector \((x_1, \ldots, x_{n-1}, 0, x_{n+1}, \ldots, x_{2n})\), ta cần tìm số lượng vector khiến \(f_{2n} = 1\).
Theo chứng minh về trọng số Hamming ở trên thì nếu \(x_{2n} = 0\) thì hàm \(f_{2n}\) (hiện là hàm \(2n - 2\) biến do \(x_n\) và \(x_{2n}\) đã cố định) sẽ luôn có giá trị \(0\). Tuy nhiên chỉ với dữ liệu này thì không đủ để biết có bao nhiêu vector khiến \(f_{2n} = 1\).
Thay đổi cách tiếp cận nhưng xét \(x_{2n} = 1\), khi đó hàm \(f_{2n}\) cũng là hàm \(2n - 2\) biến do \(x_n\) và \(x_{2n}\) đã cố định, nhưng hàm \(f_{2n}\) sẽ bằng \(1\) tại đúng \(2^{n-2} \cdot (2^{n-1} - 1)\) vectors trong số \(2^{2n-1}\) vectors đang xét. Vậy theo nguyên lý bù trừ thì \(f_{2n} = 0\) tại
Lúc này ta có thể tính
Trường hợp 2. Nếu \(x_n = 1\), tương tự, trong số \(2^{2n-1}\) vector \((x_1, \ldots, x_{n-1}, 1, x_{n+1}, \ldots, x_{2n})\) ta cần tìm xem có bao nhiêu vector khiến \(f_{2n} = 1\).
Sử dụng chứng minh cho trọng số Hamming ở trên thì
Nếu \(x_{2n} = 0\) thì
bằng \(1\) tại \(2^{n-2} \cdot (2^{n-1} - 1)\) vectors.
Nếu \(x_{2n} = 1\) thì
bằng \(1\) tại tất cả \(2^{2n-2}\) vectors.
Tổng kết lại, hàm \(f_{2n} = 1\) tại
vectors. Điều này dẫn tới \(f_{2n} = 0\) tại \(2^{2n-1} - A\) vectors.
Ở đây do \(x_n = 1\) nên khi tính \(\sum (-1)^{f(\bm{x}) \oplus 1}\) ta cần chuyển dấu
Kết hợp (11) và (12) ta có hệ số Walsh ứng với vector \(\bm{a}\) có \(a_n = 1\) là
Tương tự, tại vector \(\bm{a}'\) có \(a_{2n} = 1\) thì ta cũng có \(W_f(\bm{a}') = 2^{2n-1}\).
Theo định lí Parseval thì
vì \(f\) ở đây là hàm boolean \(2n\) biến.
Như vậy ta chỉ cần chứng minh được rằng không tồn tại vector nào khác \(\bm{a}\) và \(\bm{a}'\) có hệ số Walsh lớn hơn hoặc bằng \(2^{2n-1}\).
Thật vậy, do tính giao hoán của phép XOR (phép cộng) và phép nhân nên công thức của \(f_{2n}\) cho thấy hai bộ \((x_1, \ldots, x_n)\) và \((x_{n+1}, \ldots, x_{2n})\) có thể thay thế nhau, nghĩa là
Do đó hệ số Walsh cũng có tính đối xứng như vậy. Nếu tồn tại vector \(\bm{b}\) có hệ số Walsh \(W_f(\bm{b}) \geqslant 2^{2n-1}\) thì cũng tồn tại vector \(\bm{b}'\) khác \(\bm{b}\) có hệ số Walsh \(W_f(\bm{b}') \geqslant 2^{2n-1}\).
Khi đó ta có
Điều này vô lý theo đẳng thức Parseval nên không tồn tại vector \(\bm{b}\) có hệ số Walsh lớn hơn hoặc bằng \(2^{2n-1}\).
Như vậy giá trị tuyệt đối lớn nhất trong các hệ số Walsh là \(2^{2n-1}\), từ đó nonlinearity là
Như vậy mình đã chứng minh xong công thức cho nonlinearity.
Lời giải của team JPY và gợi ý của thầy Kolomeec¶
Sau khi hết giải thì mình hỏi ý kiến thầy Kolomeec về cách làm của mình thì có vẻ là không khớp đáp án. Đáp án là nếu ta xem hai vector \((x_1, \ldots, x_n)\) và \((x_{n+1}, \ldots, x_{2n})\) như các số nguyên, tức là
thì hàm boolean \(f_{2n}\) có giá trị \(1\) nếu \(u + v \geqslant 2^n\) và ngược lại, đạt giá trị \(0\) nếu \(u + v < 2^n\).
Gợi ý của thầy hoàn toàn khớp với bài giải của team JPY, trong đó nói rằng hàm \(f_{2n}\) là hàm kiểm tra tràn số khi cộng hai số nguyên (integer overflow). Ví dụ khi cộng hai số kiểu unsigned int thì có thể xảy ra hiện tượng tràn bit vì unsigned int chỉ có \(32\) bit. Điều này hợp lý vì CAST cipher có một phép cộng modulo \(2^{32}\), nghĩa là có liên quan đến hình vẽ.
Mình cũng sẽ dùng quy nạp để chứng minh khi \(u + v \geqslant 2^n\) thì \(f_{2n}\) nhận giá trị \(1\).
Với \(n = 1\), hàm \(f_2(x_1, x_2) = x_1 x_2\) nhận giá trị \(1\) khi \(x_1 = x_2 = 1\). Lúc này \(u = x_1 = 1\) và \(v = x_2 = 1\) nên \(u + v = 2 \geqslant 2^1\). Như vậy mệnh đề đúng với \(n = 1\).
Giả thiết quy nạp: giả sử mệnh đề đúng với \(n = k \geqslant 1\), nghĩa là hàm boolean
khi \(u + v \geqslant 2^k\) với
Với \(n = k + 1\), xét hàm
Mình cũng sẽ có bốn trường hợp cho \((y, z)\):
Khi \(y = z = 0\) thì \(f_{2k+2} = 0\) với mọi \((x_1, \ldots, x_{2k})\) nên chúng ta bỏ qua.
Khi \(y = 1\) và \(z = 0\) thì \(f_{2k+2} \equiv f_{2k}\) như chứng minh ở phần trên. Khi đó \(f_{2k+2}\) bằng \(1\) tại các vector \((x_1, \ldots, x_{2k})\) khiến \(f_{2k}\) bằng \(1\), nói cách khác là
Với \(y = 1\) và \(z = 0\) thì
Như vậy nếu \(y = 1\) và \(z = 0\) thì mệnh đề cần chứng minh đúng cho \(n = k + 1\).
Khi \(y = 0\) và \(z = 1\), chứng minh tương tự trường hợp \(y = 1\) và \(z = 0\).
Khi \(y = 1\) và \(z = 1\) thì \(f_{2k+2}\) luôn bằng \(1\), tương ứng với
Như vậy mệnh đề đúng cho \(n = k + 1\) với mọi trường hợp \((y, z)\) và ta có điều cần chứng minh.
Open competition: NSUCRYPTO lightweight cipher¶
Đây là bài 6 ở round 2.
Đề bài¶
Ghi chú
Problem for special prize
NSUCRYPTO team tổ chức cuộc thi phát triển mã khối light-weight mới.
Một số yêu cầu:
Block size là \(64\) bits.
Key size là \(80\), \(96\) hoặc \(64\) bits.
Số vòng là \(32\).
Cấu trúc xây dựng tùy ý. Nghĩa là SPN, ARX, Feistel đều có thể sử dụng, thậm chí là một cách xây dựng mới.
Thí sinh cần xem xét PRESENT light-weight cipher (2007) và cố gắng tìm ra điều có thể làm tốt hơn mã khối này.
Hãy so sánh đáp án của bạn với PRESENT: khi thực hiện, khi chống phá mã (linear, differential, algebraic, ...) và đưa ra các giải thích cần thiết.
Lời giải¶
Đây là bài có tính mở rất cao nhưng để tìm ra điều gì đó mới (và hiệu quả) trong 7 ngày là rất khó. Do đó lúc thi mình đã xây dựng một block cipher mới tốt hơn PRESENT về mặt lưu trữ, còn các tính chất khác như kháng phá mã thì mình không đề cập tới. Bài này mình được 6/10 điểm.
Về PRESENT thì mình đã có tóm tắt trong một bài viết của blog này nên mình không viết lại. PRESENT cipher là thuật toán light-weight, tức là thuật toán được thiết kế nhỏ gọn để chạy trên các thiết bị có bộ xử lý và lưu trữ nhỏ (như các hệ thống nhúng).
Cải tiến của mình dựa trên việc PRESENT sử dụng mạng SP nên sẽ cần lưu trữ phép biến đổi để mã hóa và phép biến đổi ngược để giải mã:
cần lưu trữ đồng thời S-box là \(S[x]\) và inverse S-box là \(S^{-1}[x]\);
cần lưu trữ biến đổi tuyến tính pLayer và biến đổi ngược của nó;
addRoundKey có phép biến đổi ngược là chính nó nên mình bỏ qua.
Như vậy, ta tốn hai phần bộ nhớ: một cho phép biến đổi mã hóa và một cho phép biến đổi ngược để giải mã.
Làm sao để cải tiến? Mình dùng mô hình Feistel, hoặc mô hình Feistel tổng quát (generalize Feistel network) để xây dựng mã khối mới.
Khối đầu vào (plaintext) có \(64\) bits sẽ được chia thành \(4\) phần bằng nhau, mỗi phần có \(16\) bits:
Khóa \(K\) có \(64\) bits sẽ sinh ra các khóa con \(K_0\), \(K_1\), ..., \(K_{31}\) cho \(32\) vòng.
Tại vòng thứ \(i\) với \(0 \leqslant i \leqslant 31\), \(X^{i+4}\) được tính như sau
trong đó \(F: \mathbb{F}_2^{16} \times \mathbb{F}_2^{16} \to \mathbb{F}_2^{16}\) là round function.
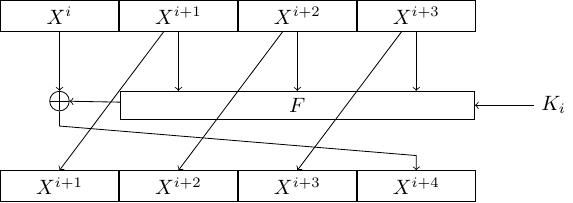
Ciphertext sau \(32\) vòng sẽ là trạng thái cuối viết theo thứ tự ngược lại, nghĩa là
Round function. Round function \(F: \mathbb{F}_2^{16} \times \mathbb{F}_2^{16} \to \mathbb{F}_2^{16}\) gồm ba phép biến đổi là cộng modulo \(2^{16}\), S-box và linear layer.
Phép cộng modulo \(2^{16}\), đặt \(Y = X^i \oplus X^{i+1} \oplus X^{i+2}\), khi đó ta tính \(Y + K_i \pmod{2^{16}}\) và kí hiệu là \(Y \boxplus K_i\).
S-box là ánh xạ \(S: \mathbb{F}_2^4 \to \mathbb{F}_2^4\), trong đó \(16\) bits từ phép cộng trên được chia thành \(4\) phần, mỗi phần có \(4\) bits đi qua S-box. Sau đó ta nối các kết quả lại thành \(16\) bits mới.
Linear layer \(L\). Ta xor \(X\) với \(X \lll 11\), trong đó \(\lll\) là phép dịch \(11\) bits sang trái.
Như vậy
với \(X = (a_0, a_1, a_2, a_3) \in \mathbb{F}_2^{16}\) và \(a_i \in \mathbb{F}_2^4\).
S-box được cho bởi bảng sau
\(x\) |
\(0\) |
\(1\) |
\(2\) |
\(3\) |
\(4\) |
\(5\) |
\(6\) |
\(7\) |
\(8\) |
\(9\) |
\(\text{A}\) |
\(\text{B}\) |
\(\text{C}\) |
\(\text{D}\) |
\(\text{E}\) |
\(\text{F}\) |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
\(S(x)\) |
\(\text{C}\) |
\(0\) |
\(\text{F}\) |
\(\text{A}\) |
\(2\) |
\(\text{B}\) |
\(9\) |
\(5\) |
\(8\) |
\(3\) |
\(\text{D}\) |
\(7\) |
\(1\) |
\(\text{E}\) |
\(6\) |
\(4\) |
Linear layer như sau:
Round key. Khóa đầu vào \(K\) có \(64\) bits sẽ được chia thành \(8\) phần \(K_0\), \(K_1\), ..., \(K_7\). Các vòng dùng khóa con như sau:
Các vòng 0, 1, ..., 7 sử dụng lần lượt các khóa \(K_0\), \(K_1\), ..., \(K_7\).
Các vòng 8, 9, ..., 15 sử dụng lần lượt các khóa \(K_0\), \(K_1\), ..., \(K_7\).
Các vòng 16, 17, ..., 23 sử dụng lần lượt các khóa \(K_0\), \(K_1\), ..., \(K_7\).
Các vòng 24, 25, ..., 31 sử dụng lần lượt các khóa \(K_7\), \(K_6\), ..., \(K_0\).
Decryption. Đẻ giải mã ta thực hiện theo thứ tự ngược lại. Giả sử ciphertext là
ta viết theo thứ tự ngược lại là
Tại vòng thứ \(i\) với \(i = 31, \ldots, 0\), \(X^i\) sẽ được tính bởi
trong đó \(F\) là round function được định nghĩa ở trên. Cuối cùng plaintext là
A nonlinear generator¶
Đây là bài 4 ở round 1 và bài 7 ở round 2.
Đề bài¶
Alice tạo ra một bộ sinh khóa như hình sau:
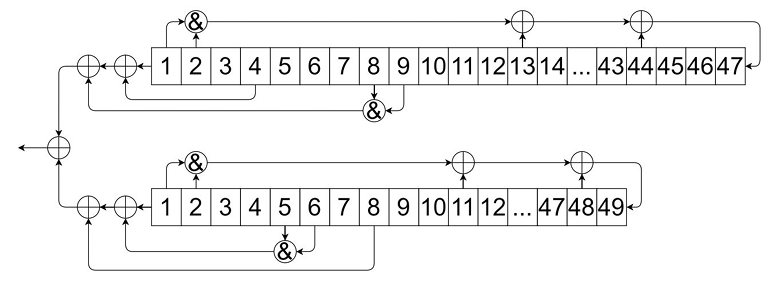
Bộ sinh khóa gồm hai thanh ghi độ dài \(47\) và \(49\) với các hàm không tuyến tính (non-linear feedback).
Tại mỗi thời điểm \(t = 1,2,\ldots\), mỗi thanh ghi sẽ sinh keystream tại trạng thái ở thời điểm \(t\) và sau đó chuyển sang trạng thái ở thời điểm \(t+1\).
Cụ thể, trạng thái của thanh ghi ở thời điểm \(t\) là
Hai thanh ghi được dịch chuyển đồng thời. Ví dụ
Keystream \(\gamma\) với độ dài \(8192\) tạo bởi bộ sinh khóa trên được ghi lại trong file keystream.txt. Ngoài ra chúng ta cũng có trạng thái \(A(8192)\) và \(B(8192)\) là:
Bạn có thể tìm lại trạng thái khởi tạo \(A(1)\) và \(B(1)\) không?
Lời giải¶
Bài này chúng ta bruteforce từ cặp bit \(A(i)\) và \(B(i)\) bắt đầu từ vị trí \(8191\) về \(1\).
Mình sẽ viết lại dãy của đề bài. Dãy trên và dãy dưới lần lượt là \(a_0, a_1, \ldots\) và \(b_0, b_1, \ldots\) và các phần tử sau được sinh ra từ các phần tử trước theo công thức
và
Keystream \(\{ g_n \}\) sẽ được sinh theo công thức
Như vậy mình sẽ bruteforce từ vị trí \(i\) từ \(8190\) về \(0\). Ở mỗi vị trí mình có hai trường hợp \(a_i\) và hai trường hợp \(b_i\). Nếu đặt được tới \(i = 0\) thì đây là dãy cần tìm.
Keystream là một chuỗi \(8192\) bits nên mình sẽ lưu ở file keystream.txt.
from itertools import product
import sys
sys.setrecursionlimit(100000)
g = list(map(int, open("keystream.txt").read()))
def check_a(val, x, i):
return x[i+47] == (val & x[i+1]) ^ x[i+12] ^ x[i+43]
def check_b(val, y, i):
return y[i+49] == (val & y[i+1]) ^ y[i+10] ^ y[i+47]
def check_g(valx, valy, x, y, z, i):
return z[i] == valx ^ x[i+3] ^ (x[i+7] & x[i+8]) ^ valy ^ (y[i+4] & y[i+5]) ^ y[i+7]
a = [-1] * 8191 + list(map(int, '00101001110001001110111001100001010100000101110'))
b = [-1] * 8191 + list(map(int, '0000010000101001000011000001010111001110000100101'))
def bruteforce(i):
if i == -1:
assert "".join(map(str, a[:47])) == "01111100001110000110010001011000110000110011110"
assert "".join(map(str, b[:49])) == "1100110011010001010101000101110100011011010010110"
return
else:
for ai, bi in product(range(2), repeat=2):
if check_a(ai, a, i) and check_b(bi, b, i) and check_g(ai, bi, a, b, g, i):
a[i], b[i] = ai, bi
bruteforce(i-1)
a[i], b[i] = -1, -1
bruteforce(8190)
Bài này được giải bởi bạn Uyên và là BEST SOLUTION. Điều thú vị là rất nhiều đội được BEST SOLUTION cho bài này :)))
Unsecure SP-network¶
Đây là bài 5 ở round 1 và bài 8 ở round 2.
Đề bài¶
Bob có nghe về mạng SP và quyết định xây dựng mật mã của riêng mình.
Block size (kích thước khối) là \(32\) bits. Bob tạo S-boxes kích thước \(2 \times 2\) là \(P\)-layer sử dụng một phần của secret key.
Ở đây \(P\) là một biến đổi tuyến tính \(P : \mathbb{F}_2^{32} \to \mathbb{F}_2^{32}\), nghĩa là
với mọi \(x, y \in \mathbb{F}_2^{32}\).
Ngoài ra, secret key là \(K \in \mathbb{F}_2^{128}\). Với nó Bob đặt
có độ dài \(32\) với mọi \(i \in \{ 1, \ldots, 100 \}\).
Như vậy vòng thứ \(i\) của mã khối sẽ như sau:
với \(x \in \mathbb{F}_2^{32}\).
Ciphertext sẽ là
với \(m\) là plaintext ban đầu, \(m = (m_1, \ldots, m_{32})\) và \(m_i \in \mathbb{F}_2\).
Tuy nhiên Bob nhanh chóng nhận ra Carol có thể đọc được plaintext mà không gặp vấn đề nếu Carol biết \(100\) cặp plaintext và ciphertext bất kì.
Tại sao cô ấy làm được?
Lời giải¶
Giả sử việc mã hóa có dạng \(C = \mathtt{Enc}(P)\). Mình sẽ chứng minh rằng với hai plaintext \(P\) và \(P'\), nếu ciphertext tương ứng là \(C\) và \(C'\) thì
Một điều khá buồn cười là bài này mình mất kha khá thời gian vì những suy nghĩ ... vĩ mô. Theo đề bài có thể nhận thấy S-box \(S\) là ánh xạ từ \(\mathbb{F}_2^2\) tới \(\mathbb{F}_2^2\). Theo quy tắc nhân có tất cả \(2^{2^2} = 16\) ánh xạ từ \(\mathbb{F}_2^2\) tới \(\mathbb{F}_2\) (số lượng hàm boolean hai biến). Do đó có \(16^2 = 256\) trường hợp S-box \(S\).
Đối với các S-box tuyến tính hoặc affine thì câu chuyện không phải vấn đề. Tuy nhiên các trường hợp khác rất khó kiểm soát. Lúc này bạn Uyên nói với mình có \(4! = 24\) trường hợp của S-box thôi, là số lượng hoán vị trên tập \(\{ 0, 1, 2, 3 \}\). Lý do là vì thuật toán mã hóa sử dụng mạng SP, do đó mỗi phép biến đổi phải có phép biến đổi ngược. Chân lý đây rồi, ánh sáng đây rồi :v :v :v Vậy mà mình nghĩ mãi, haizz.
Ý tưởng của mình là sử dụng phá mã vi sai (differential cryptanalysis).
Với ánh xạ \(M: \mathbb{F}_2^n \to \mathbb{F}_2^n\) mình gọi:
Input differential là \(x_1 \oplus x_2\).
Output differential là \(M(x_1) \oplus M(x_2)\).
Mình dùng SageMath để kiểm tra nhanh phân bố vi sai trên \(24\) hoán vị (ứng với \(24\) S-box).
import itertools
from sage.crypto.sbox import SBox
for perm in itertools.permutations(range(4)):
print(f"S-box: {perm}")
print(SBox(perm).difference_distribution_table())
print()
Một dấu hiệu chung cho mọi S-box là nếu input differential cố định thì output differential cũng cố định.
Ví dụ, với S-box tương ứng với hoán vị
thì bảng phân bố vi sai là
\(00\) |
\(01\) |
\(10\) |
\(11\) |
|
\(00\) |
\(\color{red}{4}\) |
\(0\) |
\(0\) |
\(0\) |
\(01\) |
\(0\) |
\(0\) |
\(0\) |
\(\color{red}{4}\) |
\(10\) |
\(0\) |
\(\color{red}{4}\) |
\(0\) |
\(0\) |
\(11\) |
\(0\) |
\(0\) |
\(\color{red}{4}\) |
\(0\) |
Theo bảng trên, nếu input differential là \(10\) thì output differential chắc chắn là \(01\).
Như vậy mình có nhận xét sau.
Nhận xét 13
Với S-box bất kì là hoán vị trên tập \(\{ 0, 1, 2, 3 \}\), nếu input differential cố định thì output differential cũng cố định.
Đầu tiên mình cần viết lại các kí hiệu trong bài này.
Plaintext có \(32\) bit:
S-box là hoán vị trên tập \(\{ 0, 1, 2, 3 \}\). Nói cách khác S-box là song ánh \(S\) từ \(\mathbb{F}_2^2\) tới \(\mathbb{F}_2^2\).
Đặt \(\mathcal{S}\) là ánh xạ biến đổi \(32\) bit thành \(32\) bit mới với S-box, nghĩa là
trong đó:
\(x = (x_1, \ldots, x_{32})\) là khối \(32\) bit
\(K = (K_1, \ldots, K_{32})\) là khóa con ở vòng tương ứng
\(X = (X_1, \ldots, X_{32})\) nhận được từ
Biến đổi tuyến tính là ánh xạ \(P\) từ \(\mathbb{F}_2^{32}\) tới \(\mathbb{F}_2^{32}\).
Secret key là \(K \in \mathbb{F}_2^{128}\). Subkey ở vòng thứ \(i\) nhận được từ \(K\) theo công thức
với \(i \in \{ 1, \ldots, 100 \}\). Mỗi subkey \(K^i\) có độ dài \(32\) bit.
Biến đổi ở vòng thứ \(i\) là
Ciphertext sau \(100\) vòng sẽ là
Tiếp theo, sử dụng differential attack mình sẽ tìm liên hệ known-plaintext. Mình xét vòng đầu tiên trước.
Giả sử mình có hai plaintext là
Ta có
Input differential cho S-box là
Ở đây subkey không ảnh hưởng input differential và đây là yếu tố quan trọng cần chú ý.
Nếu mình cố định input differential \((m_1 \oplus m_1', m_2 \oplus m_2')\) thì output differential
cũng cố định. Tương tự cho các cặp còn lại \((m_3, m_4)\), ..., \((m_{31}, m_{32})\).
Như vậy ở vòng đầu ta có
Suy ra
vì \(P\) là biến đổi tuyến tính. Rõ ràng nếu \(X_i \oplus X_i'\) cố định với mọi \(i = 1, \ldots, 32\) thì kết quả \(r_1(m) \oplus r_1(m')\) cũng cố định theo.
Áp dụng kết quả này cho \(99\) vòng. Ở vòng cuối (vòng \(100\)) ta XOR với \(K^{100}\) nhưng thực ra là
tức là \(K^{100}\) cũng không ảnh hưởng differential như \(K_1, \ldots, K_{99}\).
Tóm lại mình nhận được kết quả sau.
Nhận xét 14
Nếu ta biết plaintext \(P\) và ciphertext tương ứng là \(C\), thì với mọi ciphertext \(C'\) mới nào đó ta luôn có thể tìm lại được plaintext tương ứng. Nói cách khác là chú ý ở đầu bài
Chứng minh
Đặt \(DDT_S\) là ánh xạ từ input differential thành output differential của S-box. Do input differential cố định thì output differential, \(DDT_S\) sẽ nhận được từ bảng phân bố vi sai bằng cách, nếu phần tử ở hàng \(i\) và cột \(j\) bằng \(4\) thì \(DDT_S(i) = j\).
VÍ dụ, với S-box
như trên thì
Rõ ràng \(DDT_S\) là hoán vị, hay song ánh. Do đó tồn tại biến đổi ngược
Đặt \(P^{-1}\) là nghịch đảo của \(P\).
Giả sử \(c = (c_1, \ldots, c_{32})\) và \(c' = (c_1', \ldots, c_{32}')\) là các ciphertexts.
Đặt \(P^{-1}(c \oplus c') = (C_1, \ldots, C_{32})\). Áp dụng \(DDT_S^{-1}\) ta có
và tương tự cho \(98\) vòng còn lại. Cuối cùng ta sẽ nhận được differential của các plaintexts \(P\) và \(P'\).
Do đã biết \(P\) và differential \(P \oplus P'\) vừa tìm được, ta có thể tìm \(P'\).
# binmatrix.py
# https://github.com/xiangzejun/binary_matrix
# For feedback or questions, pleast contact at xiangzejun@iie.ac.cn
# Implemented by Xiang Zejun, State Key Laboratory of Information Security,
# Institute Of Information Engineering, CAS
from functools import reduce
class DataError(Exception):
"""
Define my data exception.
Check whether the elements of the matrxi are binaries.
"""
def __init__(self, x, y):
"""
store the coordinate of the entry which is not binary.
"""
self.x = x
self.y = y
def printError(self):
print("The element at [{0}][{1}] is NOT binary!".format(self.x, self.y))
class FormatError(Exception):
"""
Define my format exception.
Check whether input is a matrix or a square matrix.
"""
def __init__(self, s):
self.error = "The input is " + s
def printError(self):
print(self.error)
class RankError(Exception):
"""
Define my rank exception.
Check whether the square matrix is full rank when calculating its inverse.
"""
def __init__(self, r):
self.r = r
def printError(self):
print("The matrix is NOT full rank. (rank = {0})".format(self.r))
class BinMatrix:
def __init__(self, m = [[1]]):
"""
Initilize a matrix.
"""
self.m = m
self.r_len = len(self.m) # row number
self.c_len = len(self.m[0]) # column number
# self.length = len(self.m)
def __convertMatrixToInt(self):
"""
Convert each row of the binary matrix to an integer.
"""
return [int(reduce(lambda x , y: x + y, map(str, self.m[i])), 2)
for i in range(self.r_len)]
def __appendUnitMatrix(self):
"""
Append a unit matrix to m_int.
"""
m_int = self.__convertMatrixToInt()
return [(1 << (self.r_len + self.c_len - 1 - i)) ^ m_int[i]
for i in range(self.r_len)]
def __chooseElement(self, r, c, m_int):
"""
Choose a none-zero row started from position [r][c].
"""
err = "The row index can not exceed the column index in row-reduced echelon matrix."
assert r <= c, err
if c == self.c_len:
return None
else:
mask = (1 << (self.c_len - 1 - c))
temp = [(m_int[i] & mask) for i in range(r, self.r_len)]
if mask not in temp:
return self.__chooseElement(r, c + 1, m_int)
else:
return (temp.index(mask) + r, c)
@staticmethod
def __switchRows(r1, r2, m_int):
"""
Switch r1-th and r2-th rows of m_int.
"""
temp = m_int[r1]
m_int[r1] = m_int[r2]
m_int[r2] = temp
def __addRows(self, r, c, m_int):
"""
Add the r-th row to all the other rows if the c-th element of
the corresponding rows are nonzero.
"""
mask = (1 << (self.c_len - 1 - c))
it = list(range(self.r_len))
it.remove(r)
for i in it:
if m_int[i] & mask != 0:
m_int[i] ^= m_int[r]
def __isMatrix(self):
"""
Check whether the input is a matrix.
"""
if [len(l) for l in self.m].count(self.c_len) != self.r_len:
raise FormatError("NOT a matrix!")
else:
pass
def __isSquareMatrix(self):
"""
Check whether the input is a square matrix.
"""
if [len(l) for l in self.m].count(self.r_len) != self.r_len:
raise FormatError("NOT a Square matrix!")
else:
pass
def __isBinary(self):
"""
Check whether the entrys in the input are binaries.
"""
for i in range(len(self.m)):
for j in range(len(self.m[i])):
if self.m[i][j] not in [0,1]:
raise DataError(i, j)
else:
pass
def rank(self):
"""
Calculate the Rank of the matrix.
"""
self.__isMatrix()
self.__isBinary()
m_int = self.__convertMatrixToInt()
r = 0
c = 0
for i in range(self.r_len):
arg = self.__chooseElement(r, c, m_int)
if arg != None:
r_temp = arg[0]
c = arg[1]
self.__switchRows(r, r_temp, m_int)
self.__addRows(r, c, m_int)
r += 1
c += 1
else:
return r
return self.r_len
def det(self):
"""
Calculate the Det of the matrix.
"""
self.__isSquareMatrix()
self.__isBinary()
if self.rank() == self.r_len:
return 1
else:
return 0
def inv(self):
"""
Calculate the inverse of the matrix.
"""
self.__isSquareMatrix()
self.__isBinary()
m_adj = self.__appendUnitMatrix()
r = 0
c = 0
for i in range(self.r_len):
arg = self.__chooseElement(r, c, m_adj)
if arg != None:
r_temp = arg[0]
c = arg[1]
self.__switchRows(r, r_temp, m_adj)
self.__addRows(r, c, m_adj)
r += 1
c += 1
else:
raise RankError(r)
return [
list(map(int, list(format((m_adj[i] >> self.c_len), "0" + str(self.r_len) + "b"))))
for i in range(self.r_len)]
# cipher.py
from binmatrix import BinMatrix
import numpy as np
import random
sbox = list(range(4))
random.shuffle(sbox) # generate random S-box which is permuation
P = None
while True: # generate random invertible matrix on F_2
P = np.random.randint(2, size=(32, 32))
if np.linalg.det(P) % 2 == 1:
break
P = [row.tolist() for row in P] # convert from numpy.narray to list
P_inv = BinMatrix(P).inv() # calculate inverse of P
difference_distribution_table = [[0 for _ in range(4)] for __ in range(4)]
# i-th row -> input differential
# o-th row -> output differential
for a in range(4):
for b in range(4):
i = a ^ b
o = sbox[a] ^ sbox[b]
difference_distribution_table[i][o] += 1
sbox_diff = [0] * 4
# calculate DDT_S
for i in range(4):
for j in range(4):
if difference_distribution_table[i][j] == 4:
sbox_diff[i] = j
sbox_diff_inv = [sbox_diff.index(i) for i in range(4)] # DDT_S^{-1}
def matmul(M: list[list[int]], v: list[int]) -> list[int]:
# multiplication of matrix M and vector v
result = [0] * len(v)
for i in range(len(v)):
result[i] = sum(M[i][j] * v[j] for j in range(len(v))) % 2
return result
def encrypt(m: list[int], K: list[int]) -> list[int]:
# encryption with plaintext m, key K
Ki = [K[i:i+32] for i in range(0, len(K), 32)]
pt = m.copy()
for i in range(99):
pt = [p ^ k for p, k in zip(pt, Ki[i % 4])]
for j in range(0, len(pt), 2):
z = (pt[j] << 1) + pt[j+1] # get two bits for input of S-box
z = sbox[z]
pt[j] = z >> 1 # write two new bits
pt[j+1] = z & 1 # after S-box
pt = matmul(P, pt)
pt = [p ^ k for p, k in zip(pt, Ki[100 % 4])]
return pt
# solve.py
import random
from cipher import *
pt1 = random.choices(range(2), k = 32) # Known
pt2 = random.choices(range(2), k = 32) # Unknown
K = random.choices(range(2), k = 128)
ct1 = encrypt(pt1, K) # Known
ct2 = encrypt(pt2, K) # Known
ct_diff = [x ^ y for x, y in zip(ct1, ct2)] # ct1 ^ ct2
for _ in range(99):
ct_diff = matmul(P_inv, ct_diff)
for i in range(0, len(ct_diff), 2):
z = (ct_diff[i] << 1) + ct_diff[i+1]
z = sbox_diff_inv[z]
ct_diff[i] = z >> 1
ct_diff[i+1] = z & 1
pt2_guess = [x^y for x, y in zip(ct_diff, pt1)] # Recover pt2
assert pt2 == pt2_guess
Một điều thú vị là có thể dùng nhiều S-box và quá trình tấn công vẫn tương tự. Ví dụ
với \(S_i\) là hoán vị bất kì trên \(\{ 0, 1, 2, 3 \}\), \(i = 1, \ldots, 16\).
Ở đây ta sẽ áp dụng cùng phương pháp như trên nhưng ta sẽ tính \(DDT_{S_i}\) cho mỗi S-box \(S_i\).
Lời giải hoàn chỉnh¶
Thật ra mình đã đọc thiếu đề và chưa xét trường hợp S-box và \(P\) là các phép biến đổi bí mật (giống secret key). Đây là lý do mình không được full điểm câu này.
S-box, theo phân tích của mình ở trên, thực chất là một ánh xạ affine. Nhắc lại ánh xạ affine là ánh xạ có dạng \(S(\bm{x}) = \bm{A} \cdot \bm{x} \oplus \bm{b}\), trong đó \(\bm{A}\) là ma trận, \(\bm{x}\) và \(\bm{b}\) là các vector cột.
Khi đó, với hai đầu vào \(\bm{x}\) và \(\bm{x}'\) sao cho \(\bm{x} \oplus \bm{x}'\) cố định (input differential) thì ta có
cũng cố định do \(\bm{A}\) đã xác định.
Theo đó toàn bộ quá trình encrypt là một ánh xạ affine lớn, do đó chúng ta hoàn toàn có thể tìm được ánh xạ affine đó nếu biết đủ \(32\) vector độc lập tuyến tính.
Sử dụng cipher.py ở trên và đoạn code sau để giải:
import random
from sage.all import random_vector, vector, GF, matrix, ones_matrix
from cipher import encrypt
random.seed(1333)
K = [random.randrange(0, 2) for _ in range(128)]
ms = [random_vector(GF(2), 32) for _ in range(100)]
cs = [encrypt(list(map(int, m)), K) for m in ms]
ms = matrix(GF(2), ms)
cs = matrix(GF(2), cs)
A = matrix(GF(2), 32, 32)
b = vector(GF(2), 32)
for i in range(32):
for bb in range(2):
try:
res = ms.solve_right(cs[:, i] + bb * ones_matrix(GF(2), 100, 1))
A[:, i] = res
b[i] = bb
except:
pass
u = random_vector(GF(2), 32)
assert encrypt(list(map(int, u)), K) == list(map(int, u * A + b))
Ở đây mình viết plaintext ở dạng hàng. Giả sử plaintext và ciphertext là
Ánh xạ affine của chúng ta tương ứng với
trong đó \(\bm{A}\) là ma trận \(n \times n\) (trong trường hợp bài này \(n = 32\)).
Như vậy mình cần tìm ma trận \(\bm{A}\) và vector \(\bm{b} = (b_1, \ldots, b_n)\). Nếu có \(T\) phương trình như vậy
thì mình giải từng cột thứ \(i\) của ma trận \(A\) và từng số hạng \(b_i\). Nghĩa là
Như vậy chúng ta bruteforce \(b_1\) và kiểm tra xem phương trình có nghiệm \(\begin{pmatrix} a_{11} \\ \vdots \\ a_{n1} \end{pmatrix}\) không. Nếu có thì đây là kết quả cần tìm.
Tiến hành cho từng cột của \(\bm{A}\) và từng phần tử \(b_i\) sẽ tìm được ánh xạ affine.
Unknown function¶
Đây là bài 8 ở round 1 và bài 10 ở round 2.
Đề bài¶
Bob tạo một máy lượng tử \(M\) mã hóa 4-bit word với 4-bit secret key \(k = (k_1, k_2, k_3, k_4)\) theo mạch sau:
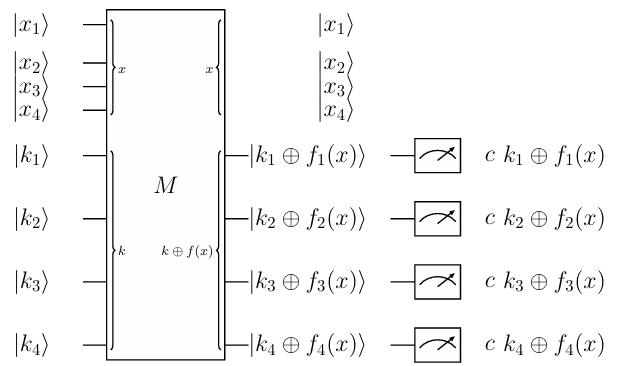
Máy này thực hiện trên 4-bit plaintext \(x = (x_1, x_2, x_3, x_4)\) với 4-qubit tương ứng, gọi là "plainstate", là \(\lvert x_1, x_2, x_3, x_4 \rangle\), tương tự với "keystate" là \(\lvert k_1, k_2, k_3, k_4 \rangle\).
Mô hình tính toán là
trong đó
là hàm Boolean vectorial khả nghịch trên \(4\) biến. Khi đó "cipherstate" là
và cuối cùng ta thu được ciphertext.
Alice có thể khôi phục secret key \(k\) không nếu cô ấy không biết hàm \(f\)?
Giả sử Alice có oracle access tới máy lượng tử với khóa cố định \(k\) và thu được thông tin
với \(c\) đã biết.
Lời giải¶
Đặt \(\bm{x} = (x_1, x_2, x_3, x_4) \in \mathbb{F}_2^4\).
Kí hiệu bảng chân trị của các hàm bool \(f_1(\bm{x})\), \(f_2(\bm{x})\), \(f_3(\bm{x})\) và \(f_4(\bm{x})\) là
\(x_1\) |
\(x_2\) |
\(x_3\) |
\(x_4\) |
\(f_1(\bm{x})\) |
\(f_2(\bm{x})\) |
\(f_3(\bm{x})\) |
\(f_4(\bm{x})\) |
|---|---|---|---|---|---|---|---|
\(0\) |
\(0\) |
\(0\) |
\(0\) |
\(m_0\) |
\(n_0\) |
\(p_0\) |
\(q_0\) |
\(0\) |
\(0\) |
\(0\) |
\(1\) |
\(m_1\) |
\(n_1\) |
\(p_1\) |
\(q_1\) |
\(0\) |
\(0\) |
\(1\) |
\(0\) |
\(m_2\) |
\(n_2\) |
\(p_2\) |
\(q_2\) |
\(0\) |
\(0\) |
\(1\) |
\(1\) |
\(m_3\) |
\(n_3\) |
\(p_3\) |
\(q_3\) |
\(0\) |
\(1\) |
\(0\) |
\(0\) |
\(m_4\) |
\(n_4\) |
\(p_4\) |
\(q_4\) |
\(0\) |
\(1\) |
\(0\) |
\(1\) |
\(m_5\) |
\(n_5\) |
\(p_5\) |
\(q_5\) |
\(0\) |
\(1\) |
\(1\) |
\(0\) |
\(m_6\) |
\(n_6\) |
\(p_6\) |
\(q_6\) |
\(0\) |
\(1\) |
\(1\) |
\(1\) |
\(m_7\) |
\(n_7\) |
\(p_7\) |
\(q_7\) |
\(1\) |
\(0\) |
\(0\) |
\(0\) |
\(m_8\) |
\(n_8\) |
\(p_8\) |
\(q_8\) |
\(1\) |
\(0\) |
\(0\) |
\(1\) |
\(m_9\) |
\(n_9\) |
\(p_9\) |
\(q_9\) |
\(1\) |
\(0\) |
\(1\) |
\(0\) |
\(m_{10}\) |
\(n_{10}\) |
\(p_{10}\) |
\(q_{10}\) |
\(1\) |
\(0\) |
\(1\) |
\(1\) |
\(m_{11}\) |
\(n_{11}\) |
\(p_{11}\) |
\(q_{11}\) |
\(1\) |
\(1\) |
\(0\) |
\(0\) |
\(m_{12}\) |
\(n_{12}\) |
\(p_{12}\) |
\(q_{12}\) |
\(1\) |
\(1\) |
\(0\) |
\(1\) |
\(m_{13}\) |
\(n_{13}\) |
\(p_{13}\) |
\(q_{13}\) |
\(1\) |
\(1\) |
\(1\) |
\(0\) |
\(m_{14}\) |
\(n_{14}\) |
\(p_{14}\) |
\(q_{14}\) |
\(1\) |
\(1\) |
\(1\) |
\(1\) |
\(m_{15}\) |
\(n_{15}\) |
\(p_{15}\) |
\(q_{15}\) |
Ở đây \(m_i\) là giá trị của hàm \(f_1(\bm{x})\) tại dòng thứ \(i\) với \(0 \leqslant i \leqslant 15\). Tương tự cho \(n_i\), \(p_i\) và \(q_i\).
Ta đã biết
với \(\bm{c}\) đã biết.
Như vậy ta có
suy ra
"Cipherstate"
chính là \(4\) bit ciphertext
Vì Alice có truy cập oracle tới máy với khóa cố định \(k\) nên
Nếu Alice gửi plaintext \((0, 0, 0, 0)\) thì sẽ nhận lại ciphertext
Nếu Alice gửi plaintext \((1, 1, 1, 1)\) thì sẽ nhận lại ciphertext
Nếu Alice gửi plaintext \((1, 0, 0, 0)\) thì sẽ nhận lại ciphertext
Nói cách khác là
Ta đã biết vector \(\bm{c}\), và có thể tính \(\bm{C}_0 \oplus \bm{C}_{15} \oplus \bm{C}_8\) nên hoàn toàn có thể tìm lại được khóa \(\bm{k}\) mà không cần hàm \(f\).
A simple hash function¶
Đây là bài 11 ở round 2.
Đề bài¶
Carol tạo một thuật toán hash mới. Khóa \(k = (k_1, \ldots, k_6)\) là vector nhị phân độ dài \(6\).
Đầu vào hàm hash là một dãy các chữ số. Dãy này được chia thành các khối độ dài \(6\). Nếu độ dài của dãy không chia hết cho sau thì ta thêm lần lượt các chữ số \(1\), \(2\), \(3\), ... vào sau dãy cho đến khi độ dài của dãy chia hết cho \(6\).
Mỗi khối, giả sử là \((p_1, \ldots, p_6)\), được biến đổi thành số nguyên theo quy tắc
Ở đây \((-1)^0 = 1\) và \((-1)^1 = -1\).
Kết quả sau khi tính toán các khối \(n_1\), \(n_2\), ... sau đó được tổng hợp thành giá trị hash là
Carol áp dụng thuật toán hash này vào hệ thống log của trang web ngân hàng. Mỗi khi người dùng nhập mật khẩu \(P\) thì hệ thống sẽ tính toán hash \(H(P, K)\) và so sánh với giá trị hash lưu trên cơ sở dữ liệu để xem người dùng có nhập đúng mật khẩu không.
Nhưng mà Carol nhận ra hệ thống này không an toàn. Việc tìm va chạm (collision) là có thể và từ đó kẻ tấn công có thể truy cập hệ thống. Họ làm như thế nào?
Hãy đề xuất thuật toán đơn giản nhất để tìm va chạm cho mọi dãy đầu vào \(P\) biết trước nếu khóa \(K\) không biết.
Hơn nữa hãy tìm va chạm ngắn nhất cho dãy trong ví dụ (dãy \(P = 134875512293\)). Lưu ý rằng do không biết \(K\) nên chúng ta cũng không biết giá trị hash \(H(P, K)\).
Lời giải¶
Bài này mình có chút nhầm lẫn nên không được full điểm.
Giả sử input có \(t\) khối là \(n_1\), \(n_2\), ..., \(n_t\). Mỗi khối có \(6\) chữ số.
Mình sẽ chứng minh rằng khi \(t\) chẵn thì ta luôn tìm được collision mà không cần khóa \(K\).
Đầu tiên, với \(t = 2\), giả sử hai khối là
Giả sử khóa là \(K = (k_1, \ldots, k_6)\). Khi đó hash là
và nếu mình tăng hoặc giảm \(p_{1, i}\) và \(p_{2, i}\), với \(1 \leqslant i \leqslant 6\), cùng một lượng, ví dụ như
và thay \(p_{1, 1}'\) và \(p_{2, 1}'\) vào hash thì được
Điều đó nghĩa là nếu tăng hoặc giảm \(p_{1, i}\) và \(p_{2, i}\) cùng lượng, tức là
và phải thỏa điều kiện \(1 \leqslant p_{1, i}' \leqslant 9\) và \(1 \leqslant p_{2, i}' \leqslant 9\) thì mình sẽ tìm được input mới có cùng hash.
Khi \(t = 4, 6, \ldots\) thì sử dụng phương pháp tương tự cho các cặp khối \(n_{2m+1}\) và \(n_{2m+2}\) (mỗi cặp sử dụng các giá trị \(a_i\) tùy ý miễn thỏa các điều kiện trên) thì ta luôn tìm được collision bất kể khóa \(K\) là gì.
Cryptographic Fish¶
Đây là bài 1 ở round 1.
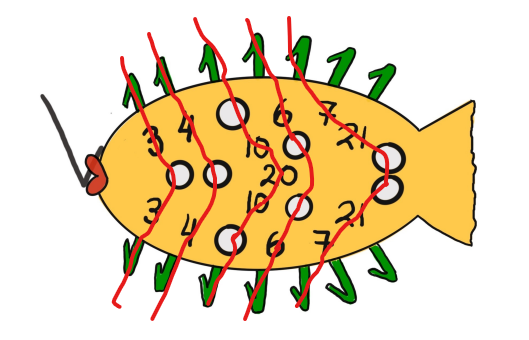
Đây là tam giác Pascal.
Mình đã có một hàng là
Hàng kế tiếp là
Hàng kế nữa là
Tiếp theo sẽ là
vì theo thứ tự chúng ta sẽ cần \(C^2_6\) (đi từ trên xuống) và \(C^4_6\) (đi từ dưới lên).
Hàng cuối sẽ là
Còn về ô đầu tiên thì cần điền số \(\color{red}2\) do dòng trước \(3\) là \(2\) theo tam giác Pascal.
Như vậy kết quả là