Google CTF 2021¶
Pythia¶
Đề bài ở file service.py.
Ở bài này random ba password từ các ký tự in thường, mỗi password có độ dài là \(3\).
Nhiệm vụ của chúng ta là tìm ba password này và ghép lại (theo thứ tự) để lấy flag.
Trong \(150\) queries, chúng ta có thể làm một trong ba việc:
chọn password để decrypt;
thử password để lấy flag;
gửi nonce và ciphertext để kiểm tra xem có thể decrypt bằng AES-GCM không.
Chúng ta sẽ cần hiểu cách AES-GCM hoạt động.
Counter mode (CTR)¶
Chúng ta bắt đầu với CTR trước.
Ở đây một bộ đếm (counter) được sử dụng. Chúng ta có thể dùng bộ đếm cơ bản \(0\), \(1\), \(2\), ... hoặc các bộ đếm phức tạp hơn. Mô hình mã hóa với khóa \(K\) là \(C_i = P_i \oplus \mathsf{Enc}_K (\text{counter}_i)\). Việc dùng bộ đếm nào cũng không quá quan trọng, qua thuật toán AES thì đều khó cả.
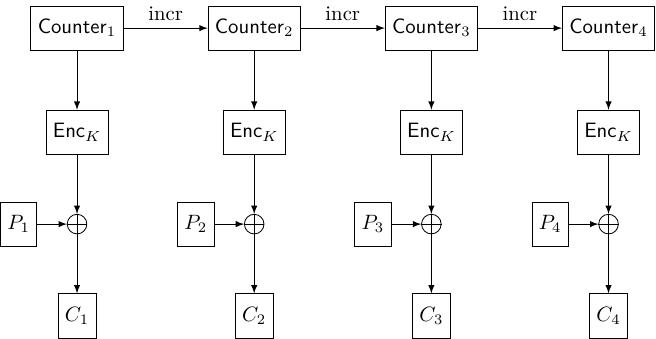
Trong AES-GCM, CTR đóng vai trò mã hóa.
Authenticated encryption (AEAD)¶
Một vấn đề quan trọng đối với mã hóa đối xứng (stream cipher và block cipher) là làm sao để kiểm tra thông tin có bị sửa đổi không?
Khi đó chúng ta thêm một trường dữ liệu gọi là associated data. Do đó mô hình mã hóa được gọi là authenticated encryption with associated data (AEAD). Chúng ta cần định nghĩa sau:
Message authentication code (MAC) là một hàm bất kì, kí hiệu là \(\text{MAC}_K (N, C, A^d)\). Sử dụng secret key \(K\) trao đổi bởi Alice và Bob, hàm lấy nonce \(N\), ciphertext \(C\) và associated data \(A^d\) nào đó để tạo ra tag \(T\). Dựa vào tag \(T\) này Bob kiểm tra tính hợp lệ của ciphertext \(C\) do Alice gửi tới.
Chúng ta có thể hiểu nonce là một giá trị khởi đầu nào đó.
Ví dụ, giả sử Alice muốn gửi cho Bob plaintext \(P\). Alice chọn nonce \(N\) và encrypt plaintext với \(C = E_K (N, P)\). Sau đó Alice tạo tag \(T = \text{MAC}_K (N, C, A^d)\) và gửi message \(M = \{N, C, T\}\) tới cho Bob.
Giả sử Bob nhận được message \(M' = \{N', C', T'\}\). Bob tính \(\tau = \text{MAC}_K (N', C', A^d)\) và so sánh với \(T'\). Nếu \(\tau = T'\) thì ciphertext không bị sai lệch, từ đó Bob có thể decrypt \(P' = D_K(N', C')\).
Galois/Counter mode (GCM)¶
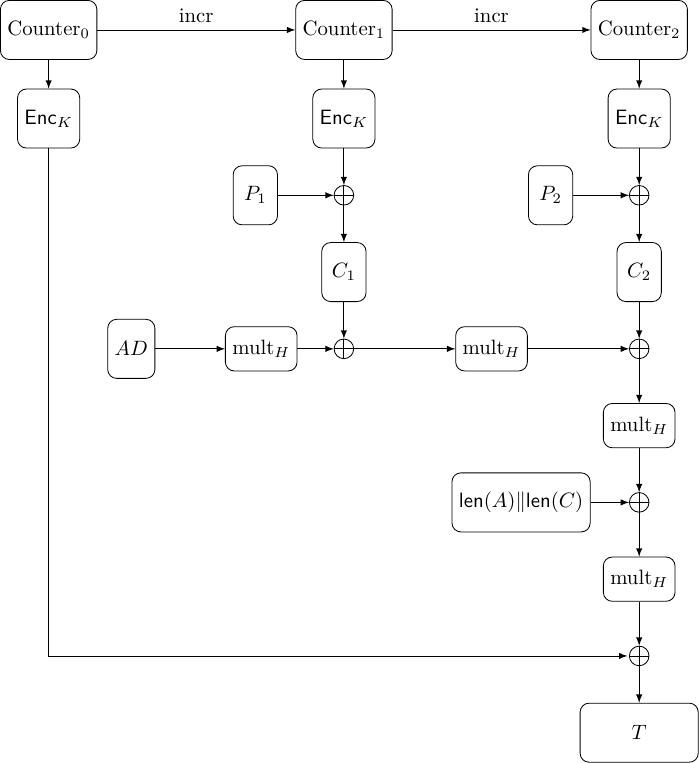
Ở GCM:
CTR được sử dụng để mã hóa các khối plaintext \(P_0\), \(P_1\), ..., \(P_{n-1}\) thành các khối ciphertext \(C_0\), \(C_1\), ..., \(C_{n-1}\);
các khối ciphertext kết hợp với associated data để tạo ra tag. Tất cả việc tính toán qua hàm \(\text{mult}_H\) hay \(C_i \oplus \text{mult}_H\) được thực hiện trên \(\mathbb{F}_{2^{128}}\) với đa thức tối giản là \(f(x) = x^{128} + x^7 + x^2 + x + 1\). Lý do của việc này là mỗi block của AES \(16\) byte, tương đương \(128\) bit, nên ta có thể chuyển đổi từ khối \(16\) bytes thành đa thức thuộc \(\mathbb{F}_{2^{128}}\).
Giả sử mình có ciphertext \(C\) gồm \(n\) block, kí hiệu là
Đối với bài CTF này thì associated data không được dùng nên mình sẽ bỏ qua.
Vậy \(H\) trong chỗ \(\text{mult}_H\) là gì? Ở đây \(H = \text{AES}_K (0^{128})\), nghĩa là encrypt một dãy gồm \(128\) bits \(0\).
Quá trình tính tag diễn ra như sau.
Với lần \(\text{mult}_H\) đầu, do không có associated data nên giá trị khởi tạo là \(0^{128}\).
Với lần \(\text{mult}_H\) thứ hai, \((0^{128} \oplus C_0) \cdot H = C_0 H\).
Với lần \(\text{mult}_H\) thứ ba, \((C_0 H \oplus C_1) \cdot H = C_0 H^2 \oplus C_1 H\).
Cứ tiếp tục như vậy nhưng để ý hai lần \(\text{mult}_H\) cuối cùng.
Độ dài toàn bộ associated data tính theo bit được biểu diễn bởi số nguyên \(\text{len}(A)\) độ dài \(64\) bits. Tương tự, độ dài toàn bộ ciphertext tính theo bit được biểu diễn bởi số nguyên \(64\) bits là \(\text{len}(C)\). Vì ở đây không có associated data nên \(\text{len}(A) = 0\) và \(\text{len(C)} = 128 \cdot n\) với \(n\) là số lượng khối và mỗi khối có \(128\) bits. Như vậy chúng ta có \(128\) bits kết quả cho \(\text{len}(A) \Vert \text{len}(C)\) là \(0^{64} \Vert (128 \cdot n)\).
Với lần kế cuối ta sẽ có
với \(L = 0^{64} \Vert (128 \cdot n)\).
Với lần cuối ta cộng thêm encrypt của \(\text{counter}_0\) nữa là xong.
Vậy kết quả cuối cùng của toàn bộ quá trình là tag
Theo cách chọn nonce của AES-GCM thì nonce có độ dài \(12\) bytes (\(96\) bits) và
trong đó \(IV\) là nonce.
Quay lại bài toán¶
Để giải bài này mình cần làm như sau:
cố định \(IV\) và \(T\);
mình chia tập hợp khóa thành hai nửa trái phải (tìm nhị phân) và kiểm tra xem key (trong bài là password) nằm ở nửa nào cho tới khi không gian key chỉ còn 1.
Tới đây, mục đích của mình là tìm các ciphertext \(C_0\), \(C_1\), ..., \(C_{n-1}\) sao cho với tất cả key trong một nửa trái đều cho ra cùng một tag.
Khi mình gửi ciphertext và tag này lên server, nếu server trả về Decryption successful nghĩa là key cần tìm nằm trong nửa trái, nếu fail nghĩa là key nằm ở nửa phải.
Để tìm được các ciphertext như vậy mình sử dụng nội suy Lagrange (Lagrange interpolation).
Mình thấy rằng
Tương đương với
Với mỗi \(K_i\) thuộc nửa trái mình có \(H_i = \text{AES}_{K_i}(0^{128})\) và \(\text{AES}_{K_i} (J_0)\) tương ứng.
Đặt \(f(x) = C_0 x^{n-1} + C_1 x^{n-2} + \cdots + C_{n-1}\). Đa thức này thỏa mãn với mọi key \(K_i\) thuộc nửa trái thì
Lưu ý rằng để tìm đa thức \(f(x)\) bậc \(m\) thì cần \(m+1\) cặp \((x_i, f(x_i))\). Do đó ở đây ta chọn \(n = \mathrm{len}(keys)\) với \(keys\) là tập chứa tất cả key của nửa trái.
Từ đó với \(n\) key mình sẽ tìm được \(f(x)\) (vì \(f(x)\) có bậc \(n-1\)).
Hàm encrypt một block AES. Hàm chuyển đối từ block \(16\) byte sang đa thức thuộc \(\mathbb{F}_{2^{128}}\) và ngược lại
def aes_ecb(key, plaintext):
return AES.new(key, AES.MODE_ECB).encrypt(plaintext)
def byte_to_pol(block):
n = int.from_bytes(block, 'big')
nn = list(map(int, bin(n)[2:].zfill(128)))
pol = sum(j*x**i for i, j in enumerate(nn))
return F(pol)
def pol_to_byte(element):
coeff = element.polynomial().coefficients(sparse=False)
coeff = coeff + [0] * (128 - len(coeff))
num = int(''.join(list(map(str, coeff))), 2)
return int.to_bytes(num, 16, 'big')
Hàm attack tìm ciphertext với danh sách key, nonce và tag
def find_poly(keys, nonce, tag):
points = []
L = byte_to_pol(b'\x00' * 8 + int.to_bytes(128 * len(keys), 8, 'big'))
T = byte_to_pol(tag)
N = nonce + b'\x00' * 3 + b'\x01'
for key in keys:
Hi = byte_to_pol(aes_ecb(key, bytes(16)))
Bi = byte_to_pol(aes_ecb(key, N))
fHi = ((L * Hi) + Bi + T) * Hi**(-2)
points.append((Hi, fHi))
lagrange = R.lagrange_polynomial(points)
coeff = lagrange.coefficients(sparse=False)[::-1]
C = b"".join([pol_to_byte(c) for c in coeff])
return C
LƯU Ý 1. Do không gian key ban đầu khá lớn (\(26^3\)) nên việc tìm nhị phân ngay từ đầu khá là khoai (đa thức bậc \(26^3 / 2 = 8788\)) nên mình chia ra các chunk key dài \(512\) để tìm chunk nào chứa key (bản chất không thay đổi). Sau đó từ mỗi chunk mình mới dùng tìm nhị phân mò key.
LƯU Ý 2. Việc tính toán đa thức bậc \(512\) cũng tốn thời gian nên chúng ta có thể tính trước rồi lưu lại trên dict hoặc hash table hoặc bất cứ thứ gì bạn nghĩ ra :v sau đó chúng ta mới giao tiếp với server.
Phần còn lại của code là attack thôi :))))
solve.py
from pwn import remote, process, context
from sage.all import *
from Crypto.Cipher import AES
from itertools import product
import string
from base64 import b64encode, b64decode
from cryptography.hazmat.backends import default_backend
from cryptography.hazmat.primitives.ciphers.aead import AESGCM
from cryptography.hazmat.primitives.kdf.scrypt import Scrypt
from tqdm import tqdm
import os
# context.log_level = 'Debug'
F2 = GF(2)['x']
x = F2.gen()
modulus = x**128 + x**7 + x**2 + x + 1
F = GF(2**128, 'x', modulus=modulus)
R = PolynomialRing(F, 'z')
z = R.gen()
NONCE = b'\x00' * 12
TAG = b'\x00' * 16
possible_keys = {}
keys = []
for a, b, c in product(string.ascii_lowercase, repeat=3):
kdf = Scrypt(salt=b'', length=16, n=2**4, r=8, p=1, backend=default_backend())
password = bytes(a+b+c, 'UTF-8')
key = kdf.derive(password)
possible_keys[key] = password
keys.append(key)
p = process(["python3", "service.py"])
CACHE = {}
chunk_size = 512
for i in tqdm(range(0, len(keys), chunk_size)):
test_keys = [key for key in keys[i:i+chunk_size]]
C = find_poly(test_keys, NONCE, TAG)
CACHE[i] = C
aes = AES.new(test_keys[0], AES.MODE_GCM, nonce=NONCE)
aes.decrypt_and_verify(C, TAG)
def attack(idx):
p.sendlineafter(b">>> ", b"1")
p.sendlineafter(b">>> ", str(idx).encode())
# phase 1
index = 0
for cache in CACHE:
C = CACHE[cache]
payload = b64encode(NONCE) + b"," + b64encode(C + TAG)
p.sendlineafter(b">>> ", b"3")
p.sendlineafter(b">>> ", payload)
p.recvline()
if b'success' in p.recvline():
index = cache
break
print(cache)
# phase 2
test_keys = [key for key in keys[cache:cache + chunk_size]]
while len(test_keys) > 1:
C = find_poly(test_keys[:len(test_keys) // 2], NONCE, TAG)
payload = b64encode(NONCE) + b"," + b64encode(C + TAG)
p.sendlineafter(b">>> ", b"3")
p.sendlineafter(b">>> ", payload)
p.recvline()
if b"success" in p.recvline():
test_keys = test_keys[:len(test_keys) // 2]
else:
test_keys = test_keys[len(test_keys) // 2:]
return test_keys[0]
password = b""
for _ in range(3):
password += possible_keys[attack(_)]
p.sendlineafter(b">>> ", b"2")
p.sendlineafter(b">>> ", password)
print(p.recvline())
print(p.recvline())
p.close()
Với mỗi password mình dùng một query để chỉ định vị trí password (\(0, 1, 2\)), \(\lceil 26^3 / 512 \rceil = 35\) query cho mỗi chunk, và \(\log_2(512) = 9\) cho tìm nhị phân. Như vậy mình tốn \((1 + 35 + 9) \cdot 3 = 135\) query tổng cộng.
Bài viết tới đây là hết. Cám ơn các bạn đã đọc.